Spark Connect 알아보기
Spark 3.4 버전에서 Spark Connect가 추가되었습니다. 간단히 정리하자면 Spark Connect는 기존 방식에서는 합쳐져 있던 Spark Driver와 Client의 역할을 명시적으로 분리해서 여러 사용자가 Spark Cluster를 공유할 때 발생하는 문제(멀티 테넌트 문제)를 완화합니다. (Spark Thrift Server를 쓸 때 이 문제 때문에 고생을 좀 했는데, 해결이 될 수도 있겠어요)
Spark Connect에 대해 알아보며 정리한 내용을 공유합니다.
문제
- 내장된 원격 연결 부재: Spark 드라이버는 클라이언트 애플리케이션과 스케줄러를 모두 실행합니다. 따라서 클러스터 근접성이 필요한 무거운 아키텍처가 됩니다. 또한 SQL 이외의 언어로는 Spark 클러스터에 원격으로 연결하는 기능이 없어서 사용자는 Apache Livy와 같은 외부 솔루션에 의존해야 합니다.
- 불편한 개발자 경험: 현재 아키텍처와 API는 대화형 데이터 탐색(노트북을 사용한 것처럼)이나 현대적인 코드 편집기에서 사용되는 풍부한 개발자 경험을 지원하지 않습니다.
- 안정성: 현재의 공유 드라이버 아키텍처로 인해 사용자가 치명적인 예외(예: OOM)를 발생시키면 모든 사용자에게 클러스터가 다운될 수 있습니다.
- 업그레이드 가능성: 현재의 플랫폼 및 클라이언트 API(예: 클래스 패스에 첫 번째 및 서드파티 종속성이 뒤섞임)의 묶음은 Spark 버전 간의 원활한 업그레이드를 허용하지 않으며, 이로 인해 새로운 기능 적용이 어려워집니다.
Spark Connect가 해결하려는 것
Spark Connect는 여러 멀티테넌트 운영 이슈를 완화합니다.
- 안정성: 너무 많은 메모리를 사용하는 애플리케이션은 이제 자신의 환경에만 영향을 미치게 되므로 Spark 드라이버와의 잠재적인 충돌을 걱정하지 않아도 됩니다. 사용자는 클라이언트에서 자체 종속성을 정의할 수 있으며 Spark 드라이버와의 잠재적인 충돌을 걱정하지 않아도 됩니다.
- 업그레이드 가능성: 이제 Spark 드라이버는 애플리케이션과 독립적으로 원활하게 업그레이드될 수 있습니다. 예를 들어 성능 개선 및 보안 수정을 활용하기 위해 업그레이드할 수 있습니다. 이것은 서버 측 RPC 정의가 역 호환성을 고려하도록 설계되었는 한 애플리케이션이 앞으로 호환될 수 있음을 의미합니다.
- 디버깅 및 관찰성: Spark Connect는 개발 중에 즐겨 사용하는 IDE에서 직접 대화식 디버깅을 가능하게 합니다. 마찬가지로 애플리케이션은 애플리케이션의 프레임워크 네이티브 메트릭 및 로깅 라이브러리를 사용하여 모니터링할 수 있습니다.
High-Level Architecture
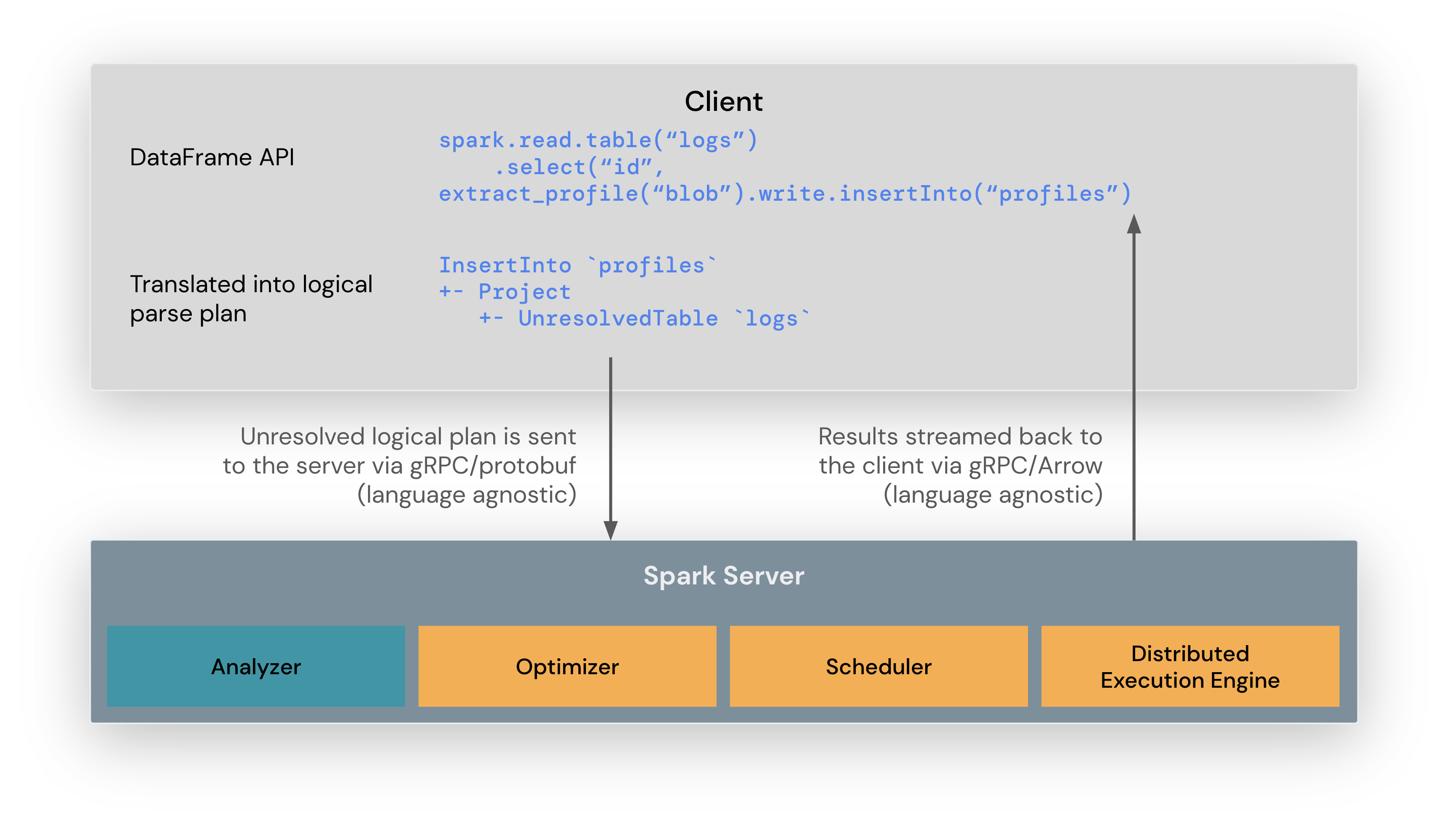
- Unlogical logical plan이 client에서 서버로 gRPC/protobuf 를 통해 전달됩니다. (Client는 튜닝되지 않은 적당히 brutal한 계획을 세우는 걸로 이해했습니다.)
- spark server 내에서 analyze, optimize, scheduling 하고 distributed execution engine 까지 처리합니다.
- 쿼리 결과는 Arrow IPC stream으로 수집되고 서버 스트리밍으로 클라이언트에 전달됩니다.
- 서버 사이드 스트리밍의 장점: 모든 결과를 드라이버에서 spooling 하지 않고 gRPC의 back-pressure와 flow-control를 활용할 수 있습니다.
“드라이버에서 스풀링하지 않는다”는 표현은 중요한 개념을 나타냅니다. 스파크(또는 비슷한 시스템)에서 쿼리 결과를 처리할 때, 결과가 매우 큰 경우 드라이버 노드의 메모리에 모든 결과를 저장하는 것이 문제가 될 수 있습니다. 이로 인해 여러 가지 문제가 발생할 수 있습니다
- 메모리 부족: 대용량 데이터를 드라이버 노드의 메모리에 저장하려면 충분한 메모리가 필요합니다. 메모리 부족으로 인해 드라이버가 다운되거나 성능이 저하될 수 있습니다.
- 성능 저하: 결과를 드라이버 노드의 메모리에 저장하면 데이터를 저장하고 검색하는 데 시간이 오래 걸릴 수 있으며, 이로 인해 쿼리 실행이 느려질 수 있습니다.
- 확장성 제한: 결과를 드라이버 노드의 메모리에 저장하는 것은 클러스터 확장성을 제한할 수 있습니다. 큰 결과 집합을 처리해야 할 때 확장 가능한 시스템이라도 드라이버 노드의 메모리 한계로 인해 처리할 수 없을 수 있습니다. 서버 측 스트리밍을 사용하는 경우, 결과를 메모리에 미리 저장하지 않고 클라이언트로 직접 스트리밍할 수 있습니다. 이렇게 하면 메모리 부족 문제가 완화되고 대용량 데이터를 처리할 수 있는 유연성이 향상됩니다. 또한 gRPC의 백프레셔 및 플로우 제어 기능을 사용하여 클라이언트와 서버 간의 효율적인 데이터 전송을 조절할 수 있습니다. 따라서 서버 측 스트리밍을 사용하면 메모리 소비를 최적화하고 성능을 향상시킬 수 있습니다. (from ChatGPT)
- Spark Connect Planner 컴포넌트는 Spark Connect 계획 노드 트리를 탐색하고 이를 Catalyst 논리 계획 노드로 변환하는 역할을 담당합니다. SQL 쿼리를 구문 분석하는 것과 유사하게, Spark Connect Planner는 초기에 항상 해결되지 않은 속성, 함수 또는 관계를 생성합니다.
- 분석 및 실행 단계에서의 오류 처리는 Spark에서 다른 쿼리 실행 프로세스와 동일하게 수행됩니다. Spark Connect Planner는 클라이언트에서 제시된 계획의 정의 순서를 정확히 따르며 어떠한 연산도 최적화하지 않습니다. SQL의 하위 쿼리와 유사하게, 비논리적인 연산(예: 필터 전에 리미트)은 오류로 간주되지 않습니다.
- (제 생각) 디버깅할 때 문법적 오류가 있다면 Driver까지 제출되기 전에 Client에서 걸러낼 것이라서, 서버 부하도 낮추고 응답 속도도 빠르겠네요.
- 대부분의 사용자는 Client interface에 상관없이 client library를 사용하게 될 것이며, client library는 interface를 래핑하고 사용자에게 Spark DataFrame API 형태로 쓸 수 있도록 높은 수준의 추상화를 제공합니다.
- end user - client library - client interface
- (제 생각) 사용자는 remote 서버에 연결하는 부분만 달라지고, DataFrame API를 통해 대부분의 작업을 할 수 있겠습니다.
-
spark = SparkSession.builder.remote("sc://localhost:15002").getOrCreate() # 이런 식으로 remote 연결
-
Execution Flow Example
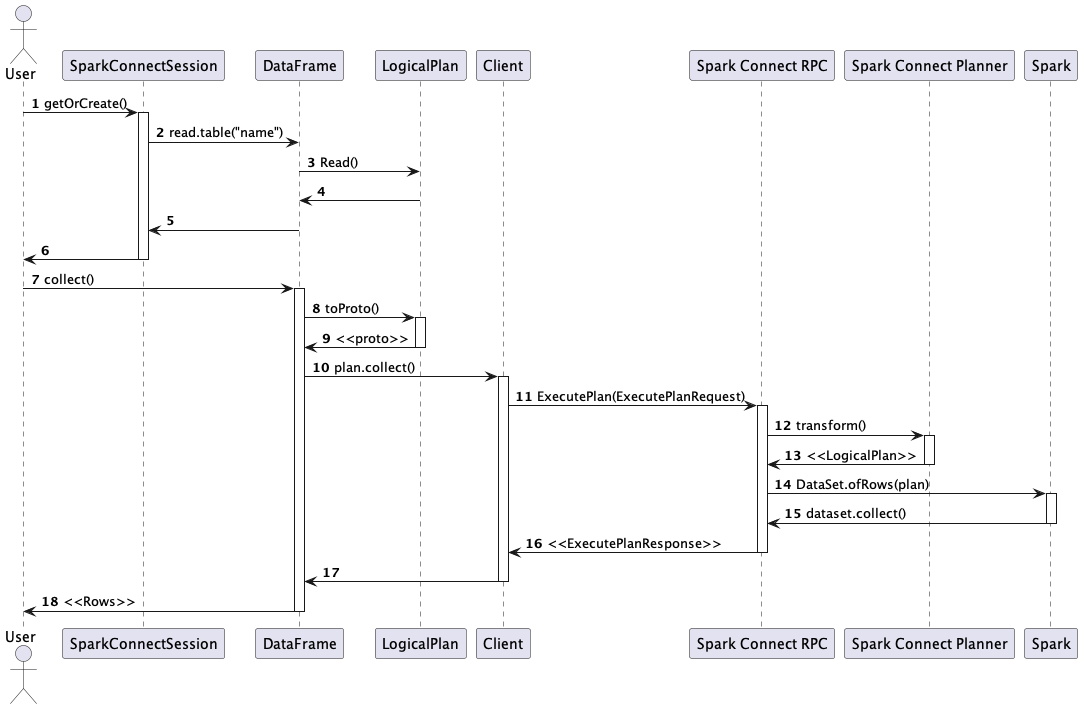
Spark Connect Session에서 collect() method를 실행하면(7) 논리 계획을 proto로 변환하고(8,9),
이걸 client가 gRPC 통신으로 Server에 보냅니다(10, 11). 그리고 서버에서 위에서 말한 것처럼 데이터를 처리해서 client로 전달해줍니다.(12-16)
아래 문서를 참고했으며, 구현된 코드와 다른 부분이 있을 수 있습니다. 더 자세한 내용이 궁금하시다면 살펴보세요.
Leave a comment