추천 시스템 - SVD
추천 시스템은 사용자들이 평가한 상품들에 대한 정보를 학습하여 아직 평가하지 않은 상품에 대한 점수를 예측하는 모델이다. 여러 추천 시스템 모델 중 Netflix Prize competition에서 좋은 성과를 거둔 SVD에 대해 정리했다.
먼저 SVD의 기초가 되는 Matrix Factorization과 SVD에 대해 간략하게 훑고, SVD를 제안한 Simon Funk의 접근을 설명한 IncrementalSVD의 Readme를 보며 정리했다. (의역과 오역의 난무가 예상된다…)
Matrix Factorization
Matrix Factorization 방법은 모든 사용자와 상품에 대해 다음 오차 함수를 최소화하는 요인 벡터를 찾아내는 것이다.
\[R \approx PQ^T\]- $R$ : m 사용자와 n 상품의 평점 행렬
- $P$ : m 사용자와 k 요인의 관계 행렬
- $Q$ : n 상품과 k 요인의 관계 행렬
$R$에 대해 조금 더 설명하자면, 1번부터 $m$번 사용자가 1번부터 $n$번 상품에 대해 점수를 매긴 것을 행렬로 표현한 것이다. 실제로는 모든 고객이 모든 상품에 대해 평가하는 것은 거의 불가능하기 때문에 드문 드문 비어있는 형태의 행렬(sparse matrix)이 된다.
SVD (singular value decomposition)
SVD(특이치 분해)는 위의 matrix factorization 문제를 푸는 방법 중 하나로, $m$ x $n$ 행렬 $R$을 3개 행렬의 곱 $USV^T$로 나타내는 것이다.
- $U$ : m × m 크기의 행렬로 역행렬이 대칭 행렬
- $S$ : m × n 크기의 행렬로 비대각 성분이 0
- $V$ : n × n 크기의 행렬로 역행렬이 대칭 행렬
여기에서 S의 대각 성분을 특이치 라고 하며, 전체 특이치 중에서 값이 큰 k개의 특이치만 사용해서 두번째 그림과 같은 행렬을 만든다.
- $\hat{U}$ : $U$ 에서 가장 값이 큰 k 개의 특이치에 대응하는 k 개의 성분만을 남긴 m×k 크기의 행렬
- $\hat{S}$ : 가장 값이 큰 k 개의 특이치에 대응하는 k 개의 성분만을 남긴 k×k 크기의 대각 행렬
- $\hat{V}$ : $V$ 에서 가장 값이 큰 k 개의 특이치에 대응하는 k 개의 성분만을 남긴 k×n 크기의 행렬
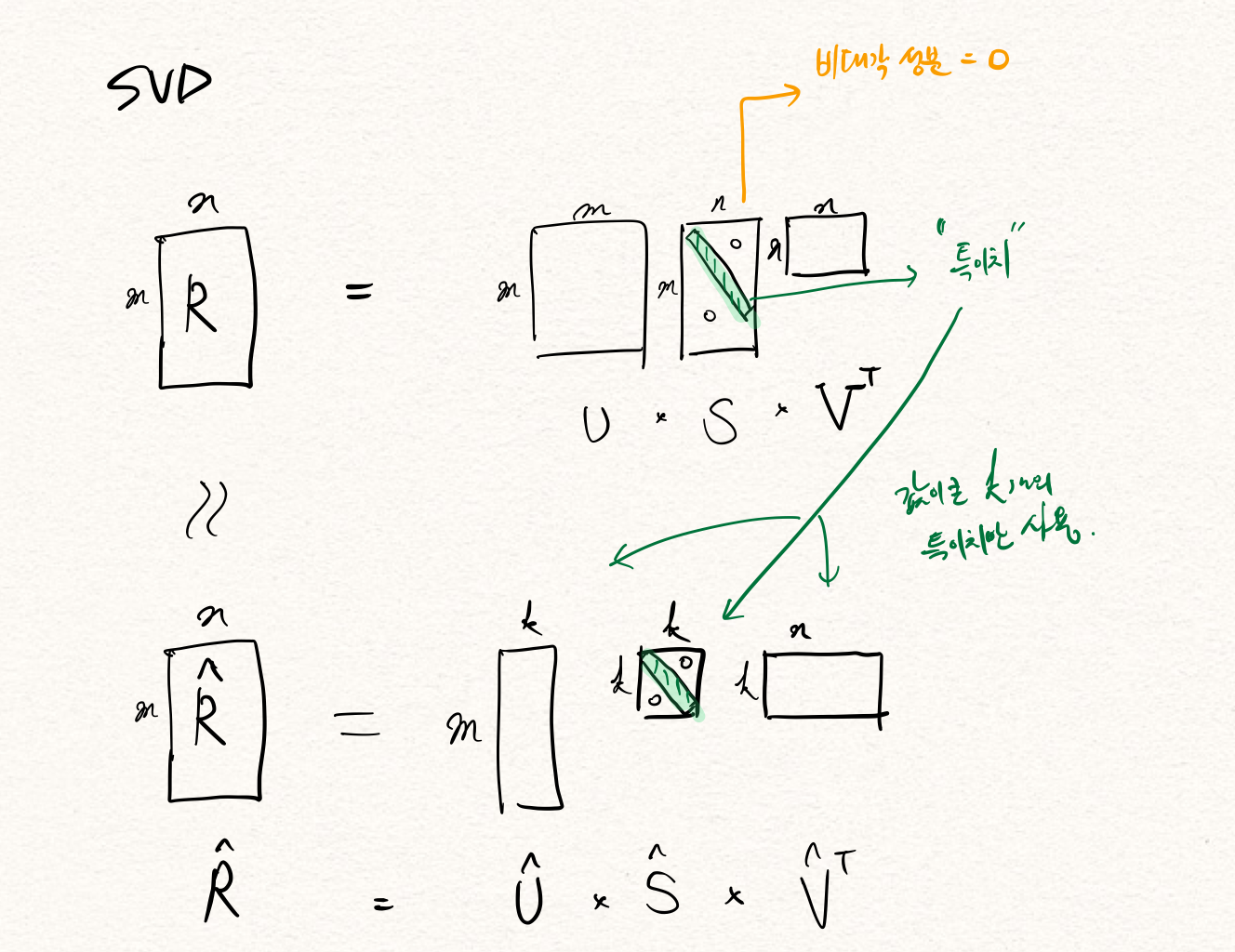
결과적으로 $\hat{R}$은 $R$을 모사하기는 하지만 $k$개의 특이치만 사용했기 때문에 일부분의 정보량 손실이 발생하는데, 마치 PCA(주성분 분석)의 효과와 비슷하다. 그리고 $R$의 비어있던 부분을 $\hat{R}$에서 재현하여 고객이 평가하지 않은 상품에 대한 점수를 예측할 수 있다.
python으로 svd를 계산하는 방법
scipy를 이용하는 것이 조금 더 정밀하다고 한다.
Why both numpy.linalg and scipy.linalg? What’s the difference?
import numpy as np
U, s, V = np.linalg.svd(M)
import scipy.linalg
U, s, V = scipy.linalg.svd(M)
[번역] 추천 시스템을 만드는 데 SVD는 어떻게 이용되는가?
영화 평점에 대한 많은 데이터가 있다고 하자. 그리고 비슷한 부류로 묶일만한 영화를 생각해보자. 자, 미국의 호러 프랜차이즈인 13일의 금요일 시리즈로 시작해보자. (13일의 금요일 시리즈는 12편 가량 개봉되었다. 나는 한편도 못 봤다.)
12편의 13일의 금요일 시리즈에 대해 고객들의 평점은 아마 일관된 경향을 보일 것이다. 시리즈에 대해 긍정적인 고객들은 전체적으로 높은 점수를, 그렇지 않은 고객들은 시리즈 각각에 모두 낮은 점수를 매길 것이다. 그리고 1편과 2편이 후속작들보다 훨씬 낫기 때문에, 13일의 금요일 시리즈를 좋아하지 않는 고객조차 후속작보다는 전작들에 조금이라도 높은 점수를 줬을 것이다.
만약 13일의 금요일 시리즈 평점에 대한 정말 간단한 모델을 하나 만들고 싶다면, 단순하게 기준점에 대한 벡터만 구성하고 -앞 2개의 시리즈는 1.0, 나머지는 0.8의 점수를 주는 방식으로- (선형 회귀 모델의 계수 값을 정해놓은 것과 같은 느낌) 현재 가지고 있는 평점 데이터에 가장 잘 맞는 벡터의 배수를 찾음으로써 각 유저의 점수를 예측하는 모델을 만들 수 있을 것이다.
한 고객이 시리즈 오직 시리즈 2편에만 5/5 점수를 줬다고 하자, 위 모델에서 우리는 단순히 기준점 벡터에 5를 곱해서 이 고객의 전체 시리즈에 대한 예상 점수를 얻을 수 있다. 1편과 2편은 5/5, 나머지는 4/5가 될 것이다. 결과 벡터는 자연스럽게 우리가 설정한 모델을 따라갈 것이고 우리가 알고 있는 고객의 실제 평점과 동일해질 것이다.
이제 갖고 있는 모든 영화 평점들을 하나의 user-by-item matrix에 때려박는다고 생각해보자. 이 matrix 어딘가에는 13일의 금요일 시리즈들에 대한 12개의 column들이 할당되어 있을 것이다. 또한, 고객이 모든 영화에 대해 평점을 입력하도록 강제할 수 없기 때문에, 그들이 입력하지 않은 부분은 matrix의 빈 부분(sparse)으로 보여진다.
12개의 13일의 금요일 시리즈만 벡터에 투영하여 본다고 했을 때, 전체를 표현하기 위해서는 크기가 12인 basis가 필요할 것처럼 보인다. -그리고 거의 맞다, 예를 들어 12명의 고객이 서로 다른 13일의 금요일 시리즈 한개씩만 평가했을 경우- 하지만 이 basis는 드문 드문 비어있는(sparse) 데이터 셋이 된다. (각각 나머지 11개의 영화에는 평가를 안 했으니) 하지만 우리가 실제로 원하는 basis는 이전 단락에서 우리가 가진 sparse 데이터를 일반화할 때 사용했던 single-vector basis와 같이 더 작은 rank를 가진 basis이다.
여기서 SVD가 쓰인다: 우리는 작은 rank를 선택할 수 있고, 정확히 그 rank의 해당하는 matrix를 SVD에서 뽑아낼 수 있다.
우리의 목표는 rank를 낮추어 평점이 매끄럽게 되도록 하는 것인데, 이를 위해서는 우리가 가진 드문 드문 비어있는 평점 데이터를 최대한 이용해서 결과 행렬이 몇 개의 basis vector로 이루어진 linear combination이 되도록 만들어야 한다. 이렇게 만든 결과 행렬은 대략적으로 원본 행렬을 모사하게 된다.
가장 좋은 부분은 심지어 추출해야 하는 정보에 대한 구체적인 도메인 지식이 필요하지 않다는 것이다. 위 케이스에서, 13일의 금요일 시리즈들에 대해 어떤 추가 정보도 있지 않았다. 그러나 우리가 충분한 앞에 설명한 선형 모델을 따르는 평점 데이터를 보유하고 있는 한, SVD는 그 영화들을 간단하게 묶어 놓을 수 있다. 왜냐하면, 비용 함수로 사용하는 잔차 제곱 합 패널티를 주는 방법이 가장 잘 먹히기 때문이다.
Leave a comment