OS - Main Memory Management
기술 발전에도 불구하고 주기억장치, 메인 메모리는 언제나 부족하다. 발전하는 만큼 프로그램도 커지기 때문이다. 효과적 사용을 위해서 다음과 같은 방법들을 사용한다.
- OS - Main Memory Management > 메모리 낭비 방지
- OS - Virtual Memory
프로그램을 메모리로
메모리 구조는 주소(address)와 데이터 (Data)로 구성되며, 프로그램 개발의 순서는 다음과 같다.
- 원천파일을 컴파일/어셈블하여 목적파일을 생성 (compiler, assembler)
- 원천파일(source file): 고수준언어 or 어셈블리언어
- 목적파일(object file): 컴파일 or 어셈블 결과
- 필요 라이브러리를 링크시켜 실행파일을 생성 (linker)
- 실행 파일을 메모리에 적재 (loader)
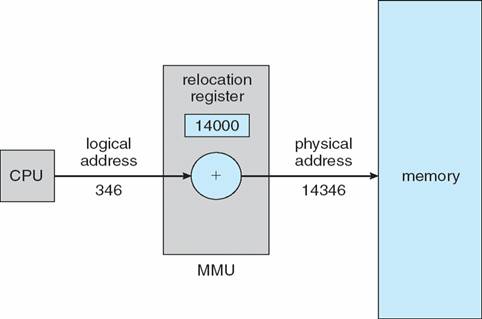
- 메모리 어디에 올릴지는 loader가 처리하고, 다중 프로그래밍 환경에서는 MMU (memory management unit) 이 한다.
MMU
CPU가 사용하는 주소(logical address)는 실제 메모리에 위치해 있는 주소(physical address)와 다르다. 이렇게 CPU가 사용하는 논리적 주소 값을 물리적 주소값으로 변환해주는 것은 MMU의 재배치 레지스터 (relocation register)가 한다. 굳이 이렇게 하는 이유는 프로그램(프로세스)이 할당된 메모리 주소값 내에서만 동작하도록 감시하기 위해서이다. 다른 프로세스 영역 침범하면? KILL
메모리 낭비 방지
Dynamic Loading
지금 당장 프로그램 실행에 필요한 코드/데이터만 메모리에 적재하는 방법이다. 프로그램이 커질수록 오류처리, 쓰이지 않는 배열 등과 같이 항상 쓰이지는 않는 부분들이 늘어나게 되고, 이런 부분들은 필요할때만 메모리에 올려 사용함으로써 메모리를 아낄 수 있다.
Dynamic Linking
여러 프로그램에 공통으로 사용되는 라이브러리는 중복으로 메모리에 적재되지 않도록 라이브러리 연결을 실행시까지 미루고, 다른 프로그램에서 라이브러리가 필요할때 이미 메모리에 올려져있는 라이브러리를 연결(Link)하도록 하는 방법이다.
- Shared library - Linux
- Dynamic Linking Library - Windows
Swapping
메모리에 적재는 되었는데, 사용되지 않는 프로세스 이미지를 메모리에서 치우는 방법이다. 다시 사용할때를 대비해서 backing store(=swap device)로 몰아낸다. 몰아낼때는 swap-out, 다시 가져올때는 swap-in 이라고 한다. Relocation register(MMU)를 사용하기 때문에 다시 가져와서는 어디에 적재해도 상관이 없다. 프로세스 크기가 크면 swapping을 할 때 I/O 부담도 증가하는데, 서버에서 backing store로 램을 쓰기도 하는 이유가 된다고 한다.
연속 메모리 할당 (Contiguous Memory Allocation)
다중 프로그래밍 환경에서 부팅 직후의 메모리에는 OS만 올라간 상태이고 big single hole처럼 큰 메모리 공간이 빈 상태가 된다. 이후에는 프로세스들의 생성과 종료가 반복되며 scattered holes이 생성된다. hole들이 불연속하게 흩어져있어 프로세스 적재가 불가능하게 되고 이런 상황을 메모리 단편화 (memory fragmentation)가 발생했다고 한다. 특히, 이처럼 빈 메모리 공간은 충분하지만 할당할 수 없는 경우를 외부 단편화 (external fragmentation)라고 한다. 연속 메모리 할당 방식은 외부 단편화를 줄이기 위해 아래와 같은 방법을 제시한다.
- First-fit: 가장 먼저 들어가는 위치에 할당
- Best-fit: 사이즈가 비슷한 위치에 할당
- Worst-fit: 사이즈가 가장 안맞는 위치에 할당
성능을 비교하자면 , 속도는 당연히 first-fit이 가장 빠르고, 메모리 이용률은 first-fit, best-fit이 높다고한다. 사실 위 방법으로 할당한다고 해도 외부 단편화로 인한 메모리 낭비는 1/3로 사용이 불가능한 수준이고, 빈 공간을 compaction해서 사용하기에는 최적 알고리즘이 없으며, 자원적으로 부담이 되는 방법이었다. 그래서 아래의 페이징이 등장했다.
페이징 (Paging)
프로세스를 일정크기(=page)로 잘라서 메모리에 올리는 방법이다. 프로세스는 페이지의 집합이고, 메모리는 프레임의 집합이다. 따라서 페이지를 프레임 단위로 할당한다고 볼 수 있다. 위에서 말했듯이, MMU 내의 재배치 레지스터 값을 바꿈으로써 MMU가 페이지 테이블 역할을 하게되고, CPU는 프로세스가 연속된 메모리 공간에 위치한다고 생각하고 작업을 하게 된다.
주소 변환 (Address Translation)
논리주소는 CPU가 이용하는 주소이며 m비트의 2진수로 표현된다. m비트 중 하위 n비트는 변위(d: displacement)가 되며, 상위 m-n 비트는 페이지 번호(p)가 된다. 페이지 번호로 대략적인 위치를 찾고, 변위로 상세 주소를 찾는다고 보면 된다. 논리주소를 물리주소로 변환할 때, 논리주소의 페이지 번호 p는 페이지 테이블 인덱스 값이 된다. 즉, p = f (프레임 번호) 이고, 상세주소인 변위(d) 는 물리주소에서도 동일하다.
예시
- page size = 4byte = 2^2 -> n= 2
- page table: 5 6 1 2
- 위와 같을 때, 논리주소 13번지의 물리주소?
- CPU가 내는 논리주소를 2진수로 변환: 13 -> 1101(2)
- 하위 n(여기서는 2) 비트는 변위 d: 01(2) -> 변위는 물리주소에서도 동일
- 상위 m-n 비트는 페이지 번호 p: 11(2) -> 3
- Page table의 3번째 값은 2 -> 2진수로 변환하면 10(2)
- 해당 물리주소는 2번째 프레임의 1 번째에 위치함: 1001(2) -> 9 (10)
내부단편화
프로세스 크기가 페이지 크기의 배수가 아니라면, 마지막 페이지는 한 프레임을 다 채울 수 없다. 이렇게 남는 공간은 메모리 낭비로 이어지고, 페이지 내부에 남는 공간이라 내부 단편화라고 한다. 그래도 내부 단편화는 외부 단편화에 비해 피해가 미미하다.
페이지 테이블
주소 변환을 위한 페이지 테이블은 MMU가 맡는데, 이 부분은 CPU 레지스터, Translation Look-aside Buffer, 혹은 메모리에서 처리할 수 있다. CPU가 제일 빠르지만 용량이 가장 부족하고, 메모리는 그 반대, 그리고 TLB는 그 사이 성능이다.
보호와 공유
보호: 모든 주소는 페이지 테이블을 경유하기 때문에, 테이블 엔트리마다 r, w, x 비트로 접근 제어가 가능하다.
공유: 같은 프로그램을 사용하는 복수개 프로세스의 경우, code + data + stack 에서 code는 공유 가능하며, 메모리를 효율적으로 사용할 수 있다. ( 단, pure code = not-self-modifying code인 경우에만)
Leave a comment