Cache와 LRU Algorithm with python code
이번에는 캐시에 대해 공부하며 정리해보았습니다.
Cache의 사용 이유와 사례
 Photo by Harrison Broadbent on Unsplash
Photo by Harrison Broadbent on Unsplash
캐시는 데이터나 값을 미리 복사해 놓는 임시 장소이다. 캐시의 접근 시간에 비해 원래 데이터를 접근하는 시간이 오래 걸리는 경우나 값을 다시 계산하는 시간을 절약하고 싶은 경우에 사용한다. - wikipedia
위의 정의처럼 캐시, 캐싱이라는 개념은 광범위하게 사용됩니다.
- 크게 보면 웹 서비스를 생각할 수 있습니다. 전 세계 사람들이 유튜브 영상을 요청하는데 그 데이터들을 매번 저장소에서 꺼내오려면 굉장히 많은 부하(=돈+시간)가 걸릴 겁니다.
- 그래서 구글은 각국 통신사마다 캐시 서버를 두어서 요청이 구글 데이터 센터로 몰려오지 않게 합니다. 나라마다 자주 요청하는 영상은 캐시 서버에서 바로 전달할 수 있게 되고, 캐시 서버에 없는 영상만 저장소에 요청하겠죠.
- 반대로 아주 작게는 CPU가 데이터를 처리할 때가 있습니다.
- 데이터를 읽을 때 L1, L2, L3 cache에 저장된 데이터가 있는지 확인하고, 없는 경우에만 Memory나 Disk에 접근합니다. 가져온 데이터는 다음에 찾을 걸 대비해서 캐시에 넣어둡니다.
- 조금 크게 생각해보면 데이터베이스(주로 RDBMS)에 쿼리 요청이 무수히 쏟아지는 상황을 생각해 볼 수 있습니다.
- DB는 데이터 요청이 들어오면 디스크를 뒤지기 전에 임시 저장소인 버퍼 캐시에 가서 최근에 요청된 데이터가 있는지 확인합니다.
- 찾는 데이터가 위치한 블록이 버퍼 캐시에 없으면 디스크로 가서 찾아야 합니다. 다만, 전체 결과의 80%가 전체 원인의 20%에서 일어나는 현상을 설명하는 파레토 법칙과 같이 대부분의 요청은 버퍼 캐시에서 해결됩니다.
- Redis는 DB의 버퍼 캐시로는 해결이 되지 않을 때 등장하는 외부 캐시 서버로 사용할 수 있습니다.
- DB 내부의 버퍼 캐시를 크-게 만들어서 외부에 두는 격이라고 보면 되겠습니다.
- key-value 형태의 데이터 저장소인 레디스는 그 자체로 DBMS(비 관계형 데이터베이스 관리 시스템)입니다.
같은 얘기를 상황만 다르게 여러 번 했습니다. 이렇듯 캐시는 여기저기서 쓰입니다.
LRU Cache
LRU(Least recently used)는 캐시 안에 어떤 데이터를 남기고, 지울지에 대해 선택하는 알고리즘 중 하나입니다. 제한된 용량 안의 cache에 데이터를 올리고, 용량이 가득 찬 경우 가장 오랫동안 사용되지 않은 값부터 버리는 방법입니다. 데이터베이스의 버퍼 캐시도, redis도 이 방식을 지원합니다. 선입선출 등의 방법도 있지만 효율성 면에서 좋지 않기 때문에 LRU를 많이 사용합니다.
혹시 다른 방법이 궁금하시다면 OS - Virtual memory > page replacement algorithms
가상메모리 관리 방식이지만 캐시 관리와 맥락이 같습니다.
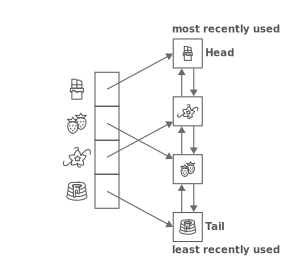 Hashmap + Doubly LinkedList
Hashmap + Doubly LinkedList
Image from LRU Cache - Data Structure
여러 방법으로 LRU를 구현할 수 있지만, 위 그림처럼 해시 맵과 이중 연결 리스트를 이용하는 방법을 소개하겠습니다. 이러면 해시 맵을 이용해 GET, PUT 모두 O(1)이고, 가장 오랫동안 찾지 않은 값도 O(1)로 찾을 수 있습니다. (항상 head 뒤에 있는 값이 됨) 다만 공간적으로 O(n)을 차지하게 됩니다.
리트코드에 LRU cache 문제가 있습니다. leetcode - LRU Cache
Code
위의 LRU를 파이썬으로는 아래처럼 표현이 가능합니다.
class Node:
def __init__(self, key, val):
self.key = key
self.val = val
self.next = None
self.prev = None
class LRUCache:
def __init__(self, max_size: int):
self.head = Node('head', 'head')
self.tail = Node('tail', 'tail')
self.head.next = self.tail
self.tail.prev = self.head
self.max_size = max_size
self.curr_size = 0
self.dic = {} # hashmap
def removeNode(self, node):
""" node의 앞 뒤를 서로 연결 """
node_after, node_before = node.next, node.prev
node_before.next, node_after.prev = node_after, node_before
def moveToEnd(self, node):
prev_node_tail = self.tail.prev
prev_node_tail.next = node
node.prev = prev_node_tail
node.next = self.tail
self.tail.prev = node
def get(self, key: int) -> int:
# 해쉬맵에서 못 찾으면 -1
if key not in self.dic:
return -1
node = self.dic[key]
node_val = node.val
# 가장 최근에 찾은 노드는 연결 리스트의 맨 뒤(앞에서부터 삭제)로 이동
self.removeNode(node)
self.moveToEnd(node)
return node_val
def put(self, key: int, new_val: int) -> None:
if key in self.dic:
node = self.dic[key]
node.val = new_val
self.removeNode(node)
self.moveToEnd(node)
else:
if self.curr_size >= self.max_size:
# 연결리스트 길이가 최대 길이를 넘어갈 경우 앞에서부터 삭제
old_node = self.head.next
del self.dic[old_node.key]
self.removeNode(old_node)
self.curr_size -=1
new_node = Node(key, new_val)
self.dic[key] = new_node
self.moveToEnd(new_node)
self.curr_size += 1
pythonic way
위의 코드는 정석적인 코드고, 파이썬의 내장 함수를 이용하면 더 짧고 편하게 구현할 수 있습니다.
리트코드 discuss에 누군가 이런 코드를 올려놨더라구요. OrderedDict를 이용해서 파이썬답게 풀어낸 것 같습니다.
class LRUCache:
def __init__(self, max_size):
self.max_size = max_size
self.dic = collections.OrderedDict()
def get(self, key):
if key not in self.dic:
return -1
val = self.dic[key]
self.dic.move_to_end(key, last=True)
return val
def put(self, key, value):
self.dic[key] = value
self.dic.move_to_end(key)
if len(self.dic) > self.max_size:
self.dic.popitem(last=False)
그런데 python 3.7 버전 이후로는 dictionary가 입력 순서를 보장합니다. (작성일 기준 3.9까지 나온 파이썬… 무섭게 올라가네요.) 그래서 아래와 같이 일반 dict를 사용해도 동일하게 동작합니다.
class LRUCache:
def __init__(self, max_size: int):
self.max_size = max_size
self.dic = {}
def get(self, key: int) -> int:
if key in self.dic:
value = self.dic.pop(key)
self.dic[key] = value # 이렇게 pop 이후 다시 입력하면 가장 뒷 순서로 배치됩니다.
return self.dic[key]
else:
return -1
def put(self, key: int, value: int) -> None:
if key in self.dic:
self.dic.pop(key)
elif len(self.dic) == self.max_size:
del self.dic[next(iter(self.dic))] # 가장 먼저 나온 (쓴 지 오래된) 값을 지웁니다.
self.dic[key] = value
마치며
캐시에 대해 대략적으로 정리해보고, 자주 사용되는 알고리즘인 LRU를 훑어봤습니다. 다음번에는 Redis에 대해 살펴보겠습니다.
Leave a comment