데이터 파이프라인과 아키텍처 변천사
데이터 파이프라인(data pipeline)은 말 그대로 파이프처럼 한 데이터 처리 단계의 출력이 다음 단계의 입력이 되는 식으로 데이터의 흐름이 연결되는 구조를 말합니다. 데이터 파이프라인을 구축하는 아키텍처도 시간이 흐르면서 바뀌어왔는데요, 이번에는 원시적인 데이터 처리 아키텍처부터 최근(2021년 말) 등장한 것까지 정리해봅니다.
0단계
DB에서 직접 데이터를 보는 단계
“서비스 데이터 분석을 해야겠다” 라고 하지만 처음에는 아무것도 없는 상태일겁니다. DB를 사용하는 서비스가 있다면 최소한 DB (RDB 혹은 NoSQL DB)에 데이터는 있으니, 일단 여기에 요청을 해서 데이터를 보겠죠. 하지만 실제 서비스를 하는 DB에 분석을 하겠다고 쿼리를 던지다보면 DB에 부담이 많아집니다. 그래서 DB에 부하를 주지 않도록 DBA나 개발자가 주로 데이터 추출 업무를 하게 됩니다. 물론 그들은 데이터 추출 외에도 다른 일을 해야하기 때문에 우선순위가 조금 밀릴 겁니다.
DB는 굉장히 비싼 자원이기 때문에 분석을 빠르게, 많이 하고 싶다고 DB 자원을 마구 늘릴 수는 없습니다. 그렇다면 DB가 별로 바쁘지 않을 때 DB에 쌓인 데이터를 가지고 와서 어딘가에 저장해놓으면 되지 않을까요? 그 어딘가를 누군가는 분석계라고 부릅니다.
1단계: Batch
1-1 Data Warehouse (DW)
분석을 위한 저장소를 준비한 단계
이제 분석계에 데이터를 적재하려고 합니다. 0단계에서 직접 호출했던 DB는 운영계라고 하구요. 용어는 팀이나 회사마다 다를 수 있지만 의미는 비슷할 거라 생각합니다. 이제 운영계와 별도로 운영되는 분석계에 데이터를 저장합니다. 그래서 큰 데이터를 요청한다던지, 복잡한 계산을 한다던지 등의 부하를 많이 주더라도 실 서비스에는 영향을 주지 않습니다.
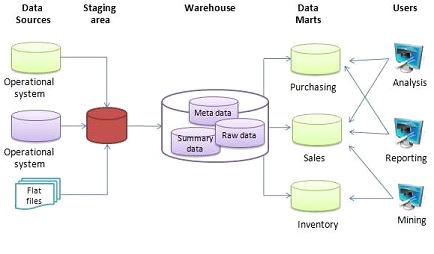
0단계에서 직접 DB에 대고 query를 던지는 행위의 대상이 되었던 DB가 Data Sources 중 하나가 됩니다. 이외에도 클라이언트에서 발생하는 로그라던지, 고객사가 전달해준 csv(excel)등 도 데이터 원천이 될 겁니다. 이런 데이터를 Warehouse에 Raw 데이터로 쌓고, 메타데이터(데이터에 대한 데이터)도 쌓게 됩니다. 그런데 이제 DW 외에 필요에 따라 데이터를 분리하고 관리할 니즈가 생깁니다.
1-2 Data Mart (DM)
데이터 사용자에게 필요한 데이터를 제공하는 단계
위 그림으로 예시를 들어보자면, 분석계가 생겼다는 얘기를 듣고 구매팀, 영업팀, 재고관리팀이 데이터를 보고 싶어합니다. 그런데 각 팀별로 필요한 데이터가 다르고, 분석을 하려는 사람이 개발자가 만들어놓은 DB 설계 그대로 복사-붙여넣기한 것 같은 Raw 데이터를 보기도 어렵습니다. 여기에 권한, 보안 문제까지 생각하면 유저가 Raw 데이터에 직접 접근하는 것은 막아야겠습니다.
그래서 팀별로 원하는 데이터 형태를 만들어 놓고, 이 데이터 마트 에서 필요한 데이터를 볼 수 있게 합니다. 이제 DW에는 DM을 만들기 위한 중간 테이블도 들어가게 됩니다. 유저들은 이제 마트에서 필요한 데이터를 찾아보게 되고, 없다면 만들어달라고 요청합니다.
Data Warehouse의 managed service로는 AWS의 분석용 RDBMS인 Redshift와 Google의 BigQuery가 있습니다. BigQuery를 잘 도입한 회사는 이거 하나면 (거의) 다 된다! 라고 하시더군요.
1-3 Data Lake (DL)
원시 데이터도 제공하는 단계
어느 정도 시간이 흐르니 데이터 사용자, 분석가들은 DM에 있는 데이터만으로는 뭔가 부족하고 아쉽습니다. Data Source나 Data Warehouse에서 개발자나 누군가가 어떤 전처리를 해서 DM을 만들어놨는데, 이제 그들은 Raw 데이터를 달라고 합니다. 사용 목적에 따라서 전처리하는 방법도 늘어났고, 분석하려는 데이터의 형태 자체도 다양해졌기 때문입니다. 이전에는 행과 열로 표현되는 구조화된 테이블이 대부분이었는데, 이제는 csv, log, json 같은 반구조화 데이터부터 오디오나 이미지 같은 비정형, Binary 데이터도 사용합니다.
그래서 이제 저장소라는 Lake에 Raw(원시) 데이터부터 가공한 데이터까지 모두 넣어놓고 찾아볼 수 있게합니다. (Lake 내에서 원시 데이터는 Raw, 가공 데이터는 Mart 등으로 구분을 위해서 나누어 놓기는 합니다.) 이 단계의 저장소는 대부분 Apache Hadoop 프레임워크의 HDFS(하둡 분산 파일 시스템)를 사용합니다.
Data Lake의 managed service로는 클라우드 서비스인 AWS의 S3, GCP의 Cloud Storage가 있는데, HDFS와 유사하게 사용할 수 있습니다. (애초에 HDFS가 Google File System(GFS)을 대체하기 위해 만들어졌답니다.)
저장소를 S3, GCS로 두고 컴퓨팅은 Athena와 Bigquery 같이 쓴 만큼 지불하는 도구를 쓰거나, EMR이나 Dataproc 같은 Managed cluster를 띄워놓고 사용할 수도 있습니다.
혹은 snowflake나 databricks의 제품을 사용해서 멀티 클라우드 환경에서 운용할 수도 있고, 추가된 편의 기능을 사용할 수도 있을 겁니다. 갈수록 좋아지고 있어요!
Pipeline
이제 어떻게 적재할지는 정했으니, 데이터가 각 요소에 채워져야합니다. 뭘 해야할까요? 데이터를 읽어서, 처리하고, 저장하면 됩니다. 이 과정을 ETL(Extract-Transform-Load)이라고도 합니다. Source로부터 전처리 과정을 거쳐 데이터가 DW, DM 혹은 DL 저장되고, 원하는 곳으로 흐르게 됩니다.
ETL은 다양한 방법으로 할 수 있습니다. 데이터가 크지 않다면 python으로도 충분할 수 있고, 대용량이라면 spark를 고려해볼수도 있고, serverless로 하고 싶다면 aws glue에서 script를 돌릴 수도 있을 겁니다.
그런데 추출을 위한 SQL 파일을 열어서, 데이터베이스에서 데이터를 추출하고, 그걸 사람이 직접 분석계 어딘가에 업로드하고, 그걸 다시 읽어서 전처리 코드를 돌리고, 결과가 나오면 그걸 또…(반복)… 하려면 파이프라인 하나 돌리기도 벅찹니다. 데이터 소스가 늘어나면 더 힘들어 질 것이고, 처리 과정이 복잡해지거나 의존성이 생기면 더 더 힘들어집니다. 그래서 이 과정이 자동화가 필수가 되고, Airflow 같은 workflow orchestration tool이 탄생했습니다.
Airflow를 이용하면 지정된 시간에 A 작업을 시작하고, 끝나면 B, C 작업을 시작하고, 중간에 작업이 실패하면 최대 N회 까지 재시도하고, 작업 재시도, 실패, 성공 여부는 email, slack, 혹은 어딘가로 연락이 오게 하고, … 등 이 예시보다 더 복잡한 일들을 비교적 쉽게 시작할 수 있습니다.
지정된 시간에 지정된 명령어를 실행하는 crontab을 지나 Ochestration 도구로 Luigi, Azkaban, NiFi 같은 대체재가 있었는데 요즘은 Airflow로 대동단결하는 것 같습니다. GCP의 workflow managed service인 composer도 내부는 airflow로 되어있습니다. 사실 말이 어렵지 Airflow도 기능이 매우 많은 crontab 입니다.
pipeline 부분을 어디에 끼워넣어야 하나.. 하다가 여기에 넣어봅니다.
1.5단계: Lambda Architecture
1단계에서는 배치 데이터만 다뤘습니다. Batch라 함은 한국말로 일괄처리 입니다. 일정 기간의 텀을 두고 데이터를 모아놨다가 한꺼번에 처리합니다. 하루 단위 배치로 처리되는 시스템에서는 오늘 유저의 행동은 분석계에서 내일 볼 수 있습니다. 주 단위라면 일주일을, 월 단위라면 한 달을 기다려야 합니다.
실시간으로 들어오는 로그 데이터 처리는 어떻게 하나요? 를 해결하기 위해 람다 아키텍처(Lambda Architecture)가 나타났습니다.

위쪽의 파이프라인은 1단계 배치를 유지하면서(batch layer), 아래쪽 실시간(스트림) 파이프라인을 추가합니다(speed layer). 실시간 처리에서는 빠른 결과를, 배치 처리에서는 정확한 결과를 제공하여 두 결과를 병합하여(실시간 처리의 부정확한 결과는 버리면서) 사용합니다.
람다 아키텍처는 배치의 늦은 지연 시간을 보완하기 위해 개발되었지만, 유지 보수가 어렵고, 동일한 데이터 처리를 두 번 구현해야하는 단점이 있습니다.
2단계: Streaming
2단계인 Streaming 처리는 1.5단계에서 빠르지만 부정확했던 speed layer의 발전으로 나타났습니다. 빠르지만 부정확하다는 것이 스트림 처리의 단점이었는데, 부정확을 정확으로 바꾸면 단점이 없어지니까요. 대표적으로 Apache Flink가 있습니다.
![]()
스트림 처리 방식도 바뀌었는데요, 이전에는 batch의 주기를 굉장히 줄여서 짧은 범위의 배치를 지속하는 방식(micro batch processing)이었다면 이제는 스트리밍 데이터를 실시간을 처리하는 방식으로 진화했습니다. (저도 처음에는 실시간 처리면 당연히 ‘실시간’으로 처리해야하는 거 아니야? 라고 생각했지만 데이터가 유실되거나, 중복으로 들어오거나의 처리를 해야해서 상당히 어려운 문제입니다.) Flink에서는 배치 처리를 스트림 처리의 특수한 경우로 간주됩니다.
Flink Vs. Spark: Difference Between Flink and Spark [2021]
마무리
많은 기업들이 이제 0단계를 벗어나 1단계 ~ 1.5단계에 머물고 있는 것 같습니다. 2단계는 많지 않은 듯 하구요. 그리고 이번 글에서 발전 흐름에 따라 단계별로 작성하긴 했지만, 0단계를 벗어나고 부터는 조직의 특성에 맞게 데이터 아키텍처, 파이프라인을 구성하면 됩니다. 그게 Data warehouse일 수도 있고, Data Lake일 수도 있을 겁니다.
2단계가 최신이니 당연히 제일 좋은 걸로 구축해야지!는 그리 좋은 생각이 아닙니다. 아키텍처든 파이프라인이든 도구고 수단이니, 목적이 뭔지에 따라 필요하면 가져다 쓰면 그만입니다. 그래서 게임이나 광고, 추천처럼 유저의 실시간 행동을 기반으로 그에 맞는 액션을 취해야 하는 분야에서는 실시간을 빠르게 도입할 유인이 있지만, 그 외 도메인 특성상 실시간이 꼭 필요하지는 않은 영역에서는 (당분간은) 1단계 수준을 잘 유지하면 될 것 같습니다. 다만, 엔지니어 입장에서는 새로운 기술이 나오면 관심있게 지켜보고 따라가는 것이 좋겠습니다. 필요하면 가져다 써야하니, 대비해야죠.
감사합니다.
Leave a comment