비전공자가 이해한 Hadoop
빅-데이터 세상에서, 데이터의 규모가 조금만 커져도 컴퓨터 한대로는 단순히 데이터를 불러오는 것조차 힘겨워지는 경우가 생긴다. 이를 해결하기 위해 Hadoop 을 이용하는 경우가 많아졌다. 데이터 엔지니어의 롤을 가진 분들이 주로 활용하는 툴.
Hadoop
High-Availability Distributed Object-Oriented Platform
- 분산 처리를 지원하는 자바 기반의 프레임워크
하둡의 장점
하나의 컴퓨터에서 처리할 수 없는 대용량의 데이터를 나누어 처리하기 위해 사용
- Computing power : 다수 CPU, RAM 이용 가능
- Fault tolerance : Cluster를 구성하는 Node 중 일부가 죽어도 복구 가능
- Flexibility : 다수의 언어 지원, 비-구조적 데이터를 필요할 때 구조적 데이터로 변환
- Low cost : 대용량 데이터 처리 비용이 RDBMS에 비해 훨씬 저렴
- Scalability : 추가 성능이 필요할 때, 확장이 용이
하둡의 기본 구성
- HDFS (Hadoop Distributed File System)
- 하둡 분산 파일 시스템
- MapReduce
- 분산 처리 프레임 워크
- YARN (yet another resource negotiator)
- 클러스터 자원 관리
위 기반을 바탕으로 Hive, Hbase, Spark, Pig, Mahout 등의 application 생태계가 구성됨
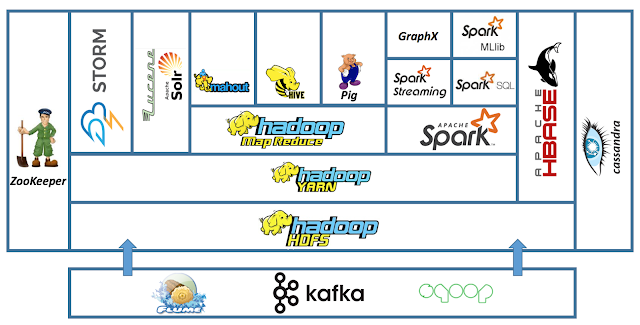
위 그림은 간략한 하둡 생태계, 실제로는 훨씬 많다. Image Source
하둡의 이름과 로고인 노란 코끼리는 하둡 개발자 아이의 장난감에서 따왔다고 한다.
HIVE
하둡 시스템의 데이터베이스
- HiveQL을 맵리듀스 작업으로 변환하고 하둡 환경에서 실행
- 관계형 데이터베이스는 아니지만, SQL 기반 명령어 사용 가능
Spark
맵리듀스와 유사한 클러스터 컴퓨팅 프레임 워크
간단 환경 설정
VirtualBox - hortenworks sandbox (하둡이 설치된 머신을 받아 쓰기만 하면 된다.) data source - GroupLens Research: ml-100k
- Web interface
- http://127.0.0.1:8888/ 로 접속
- CMD 명령어
- Putty, ssh, http://127.0.0.1:4200/ 등으로 HDFS의 명령행에 접근이 가능하다.
- 일반적인 linux 명령어 사용 가능
- root 권한이 없으면 각 노드의 filesystem만 조작이 가능. 필요시
sudo su혹은 루트 계정으로 로그인 - Hadoop File System 조작예)
hadoop fs -ls
MapReduce
하둡의 분산 처리 프레임워크
맵리듀스는 맵과 리듀스를 통칭해 부르는 것이다. 맵(Map)은 입력 파일을 한 줄씩 읽어서 데이터를 변형(transformation)하며, 리듀스(Reduce)는 맵의 결과 데이터를 집계(aggregation)한다.
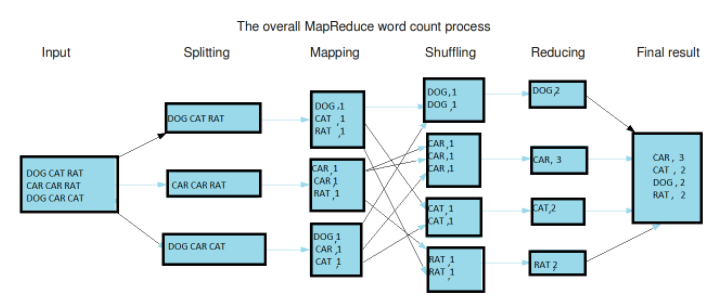
- 입력 파일을 읽는다.
- 각 행을 mapper에 전달
- mapping : 모든 key를 value 1로 매핑한다.
- 키를 섞고, 정렬
- reducing : key별로 출현횟수를 합산
- 하나의 파일로 모은다.
Apache Mesos 같은 클러스터 관리자를 사용할 수 있다.
from mrjob.job import MRJob
from jrjob.step import MRStep
class RatingsBreakdown(MRJob):
def steps(self):
return [
MRStep(mapper=self.mapper_get_ratings,
reducer=self.reducer_count_ratings),
MRStep(reduce=self.reducer_sorted_output)
]
def mapper_get_ratings(self, _, line):
(userID, movieID, rating, timestamp) = line.split('\t')
yield movieID, 1 # key, value
# reducer로 넘어갈때 key기준으로 정렬. 다만, string으로 취급함
def reducer_count_ratings(self, movieID, count):
yield str(sum(count)).zfill(5), movieID #key, value
# 먼저 넘겨준 total count 기준으로 정렬
def reducer_sorted_output(self, count, movies):
for movie in movies:
yield movie, count
# 정렬된 영화들을 하나씩 리턴
if __name__ == '__main__':
RatingsBreakdown.run()
위와 같은 방식으로 mapper와 reducer를 정의해서 사용이 가능하다. 아래는 이렇게 만든 MapReduce 파일을 사용하는 방법
Run with local (for test)
python RatingsBreakdown.py u.data
Run with Hadoop
python RatingsBreakdown.py -r hadoop --hadoop-streaming-jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar u.data
Leave a comment