비전공자가 이해한 Hadoop - Pig
피그(Pig)는 대용량 데이터 집합을 분석하기 위한 플랫폼으로 아파치 하둡(Apache Hadoop)을 이용하여 맵리듀스(MapReduce)를 사용하기 위한 높은 수준의 스크립트 언어와 이를 위한 인프라로 구성되어 있다. - wiki
Pig?
 MapReduce와 TEZ를 사용하기 쉽게 만들어주는 스크립트 언어를 제공한다.
MapReduce와 TEZ를 사용하기 쉽게 만들어주는 스크립트 언어를 제공한다.
- SQL과 비슷한 문법을 가진다.
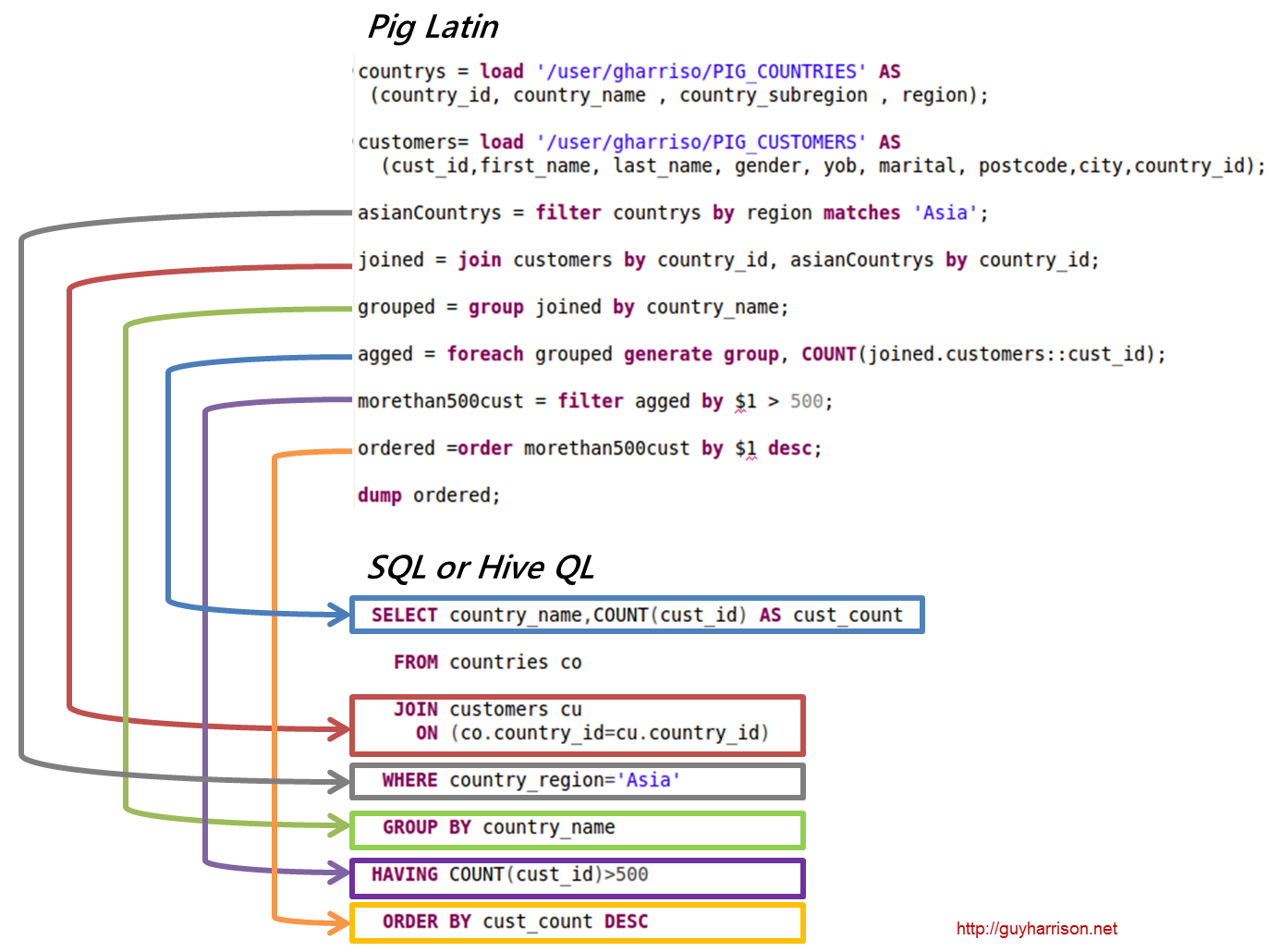
TEZ?
Pig의 스크립트를 처리하면서 가장 빠른 방법을 찾아주는 툴
- TEZ를 사용하지 않았을 때 보다 최소 2배는 빠르다.
Running pig
- Grunt
- Script
- Ambari / Hue
명령어
LOAD STORE DUMP
- STORE ratings INTO ‘outRatings’ USING PigStorage(‘\t’);
FILTER DISTINCT FOREACH/GENERATE MAPREDUCE STEAM SAMPLE
JOIN single tuplt 반환 / COGROUP -separate tuple 반환
GROUP - basically reduce
CROSS CUBE
ORDER RANK LIMIT
UNION SPLIT
DESCRIBE EXPLAIN ILLUSTRATE
UDF’s (user defined fucntion)
REGISTER DEFINE IMPORT 로 사용 가능
Ex: find the oldest movie with 5-star rating using Pig
# LOAD
ratings = LOAD '/user/maria_dev/ml-100k/u.data' AS
(userID:int, movieID:int, rating:int, ratingTime:int);
metadata = LOAD '/user/maria_dev/ml-100k/u.item' USING
PigStorage('|')AS (movieID:int, movieTitle:chararray, releaseDate:chararray, videoRelease:chararray, imdLink:chararray);
nameLookup = FOREACH metadata GENERATE movieID, movieTitle, ToUnixTime(ToDate(releaseDate, 'dd-MMM-yyyy')) AS releaseTime;
# GROUPING
ratingsByMovie = GROUP ratings BY movieID;
avgRatings = FOREACH ratingsByMovie GENERATE group AS movieID, AVG(ratings.rating) AS avgRating;
# FILTER
fiveStarMovies = FILTER avgRatings BY avgRating > 4.0;
# JOIN
fiveStarsWithData = JOIN fiveStarMovies BY movieID, nameLookup BY movieID;
DESCRIBE fiveStarsWithMovies; # to Check
# ORDER
oldestFiveStarMovies = ORDER fiveStarsWithData BY nameLookup::releaseTime;
DUMP oldestFiveStarMovies;
Quiz
- Find all movies with an average rating less than 2.0
- Sort them by the total number of ratings
Ans
ratings = LOAD '/user/maria_dev/ml-100k/u.data'
AS (userID:int, movieID:int, rating:int, ratingTime:int);
metadata = LOAD '/user/raj_ops/ml-100k/u.item' USING PigStorage('|')
AS (movieID:int, movieTitle:chararray);
nameLookup = FOREACH metadata GENERATE movieID, movieTitle;
ratingsByMovie = GROUP ratings BY movieID;
Ratings = FOREACH ratingsByMovie GENERATE group AS movieID,
AVG(ratings.rating) AS avgRating,
count(ratings.rating) AS countRating;
badMovies = FILTER avgRatings BY avgRating < 2.0;
results = JOIN badMovies BY movieID, nameLookup BY movieID;
results = FOREACH results GENERATE
badMovies::movieID AS MovieID,
badMovies::avgRating AS avgRating,
badMovies::countRating AS countRating,
nameLookup::movieTitle AS MovieTitle;
results = ORDER results BY countRating desc;
DUMP results;
세줄 요약
- Pig는 MapReduce를 간단하게 하는 도구이며,
- SQL과 비슷한 문법을 가졌다.
- 성능을 위해 TEZ 위에 올려 쓰자.
Leave a comment