Hive Table 다루기
스파크는 하이브 메타스토어를 사용하기 때문에 하이브와 연동이 자연스럽습니다. 이번 포스트에서는 하이브 테이블의 생성, 삭제, 삽입, 변경 등을 알아보겠습니다. 하이브에는 관리형 테이블과 외부 테이블이라는 생소한? 개념이 있습니다.
하이브는 애초에 OLTP가 아닌 하둡의 데이터 웨어하우징용으로 설계되었기 때문에 RDBMS와는 다릅니다. 일단, delete와 update가 불완전합니다.
없다고 보시면 됩니다
테이블 생성
외부 테이블
외부 테이블(External Table)은 이미 하둡에 데이터가 있는 데이터를 기반으로 테이블을 만들기 때문에 스키마만 정해주면 됩니다. 그래서 파일 따로, 스키마 따로 관리하기 좋습니다. 그럴 일이 있어서는 안되겠지만 누군가 테이블을 날려버려도 데이터는 안전합니다!
csv
가장 많이 쓰이는 포맷인 것 같습니다.
CREATE EXTERNAL TABLE tb_sample(
col1 STRING,
col2 INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/file/path/some/where';
parquet
컬럼 기반 저장 포맷으로, 스키마와 함께 데이터를 압축하여 저장합니다. 압축형태라 Hue에서 내용을 확인할 수 없다는게 단점.
CREATE EXTERNAL TABLE tb_sample(
col1 STRING,
col2 INT
)
STORED AS PARQUET
LOCATION '/file/path/some/where';
json
유연성이 높은 json입니다. 쌓아야할 데이터의 구조가 바뀔 가능성이 있다면 json이 좋습니다.
CREATE EXTERNAL TABLE tb_sample(
col1 STRING,
col2 STRING,
col3 STRUCT <
s_1:STRING,
s_2:INT
>
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
STORED AS TEXTFILE
LOCATION '/file/path/some/where';
관리형 테이블
관리형 테이블(Internal Table)을 생성하면 파일이 기본 저장 경로인 /user/hive/warehouse에 저장됩니다. 외부 테이블과 다르게 drop 하면 데이터와 스키마가 함께 삭제되기 때문에 주의해야합니다.
CREATE TABLE tb_sample (
userid BIGINT,
viewTime INT,
`한글컬럼명` STRING COMMENT '혹시 한글 컬럼명으로 쓰고 싶다면 backtic으로 감싸주세요'
)
COMMENT '테이블 코멘트'
PARTITIONED BY (year INT, month INT)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS;
한글 컬럼명을 쓰신다면 select 할때도 백틱을 꼭 써줘야합니다.
파티션
위처럼 파티션을 나눠주면 여러모로 관리가 편합니다.
- 재작업시 해당 파티션에만 덮어쓰기(
overwrite)가능 - where 조건에 포함하여 쿼리 시간&비용 감소
더 자세한 내용은 Hive Partition 다루기에서!
클러스터
위 예제는 hash 함수를 통과한 userid들을 32개의 버킷으로 나누어 저장하고, 버킷안에서는 viewTime을 기준으로 정렬합니다. 쿼리 효율에 도움이 된다네요.
테이블 > 파티션 > 버킷
데이터 삽입
관리형 테이블을 사용할 때는 파티션이 설정되어 있다면 insert 후에 자동으로 파티션이 추가됩니다. 외부테이블이라면 insert 구문을 사용하거나 직접 해당 경로에 데이터를 갖다놓고 파티션을 추가할 수도 있습니다.
Insert Into
INSERT INTO tb_sample
PARTITION (YEAR=2020, MONTH=06)
SELECT * FROM some_data
WHERE year=2020 and month=06;
Insert Overwrite
INSERT OVERWRITE TABLE tb_sample --덮어쓰기 구문
PARTITION (YEAR=2020, MONTH=06)
SELECT * FROM some_data
WHERE year=2020 and month=06;
테이블 변경
컬럼명 변경
ALTER TABLE tb_sample CHANGE old_col new_col STRING;
특이하게 change를 씁니다.
파일 인코딩 변경
외부 테이블 데이터의 인코딩이 euc-kr 등으로 되어있는 경우, 변경이 필요합니다. (기본값은 utf-8)
ALTER TABLE tb_sample SET SERDEPROPERTIES ('serialization.encoding'='euc-kr');
기타
Refresh Table
REFRESH TABLE tb_sample
스파크로 하이브 테이블을 사용하고 있는데 해당 테이블의 변경이 일어났을 때(주로 파티션이 추가되거나 복구된 경우가 많음), 이 명령으로 캐시된 테이블을 지우고 다시 불러올 수 있습니다. 방금 전까지 잘 되던 테이블 조회가 안된다면 에러메세지에 refresh table 하라고 써있는 경우가 많습니다.
Describe Formatted
하이브 테이블의 상세 사항을 조회할 수 있습니다.
DESCRIBE FORMATTED tb_sample;
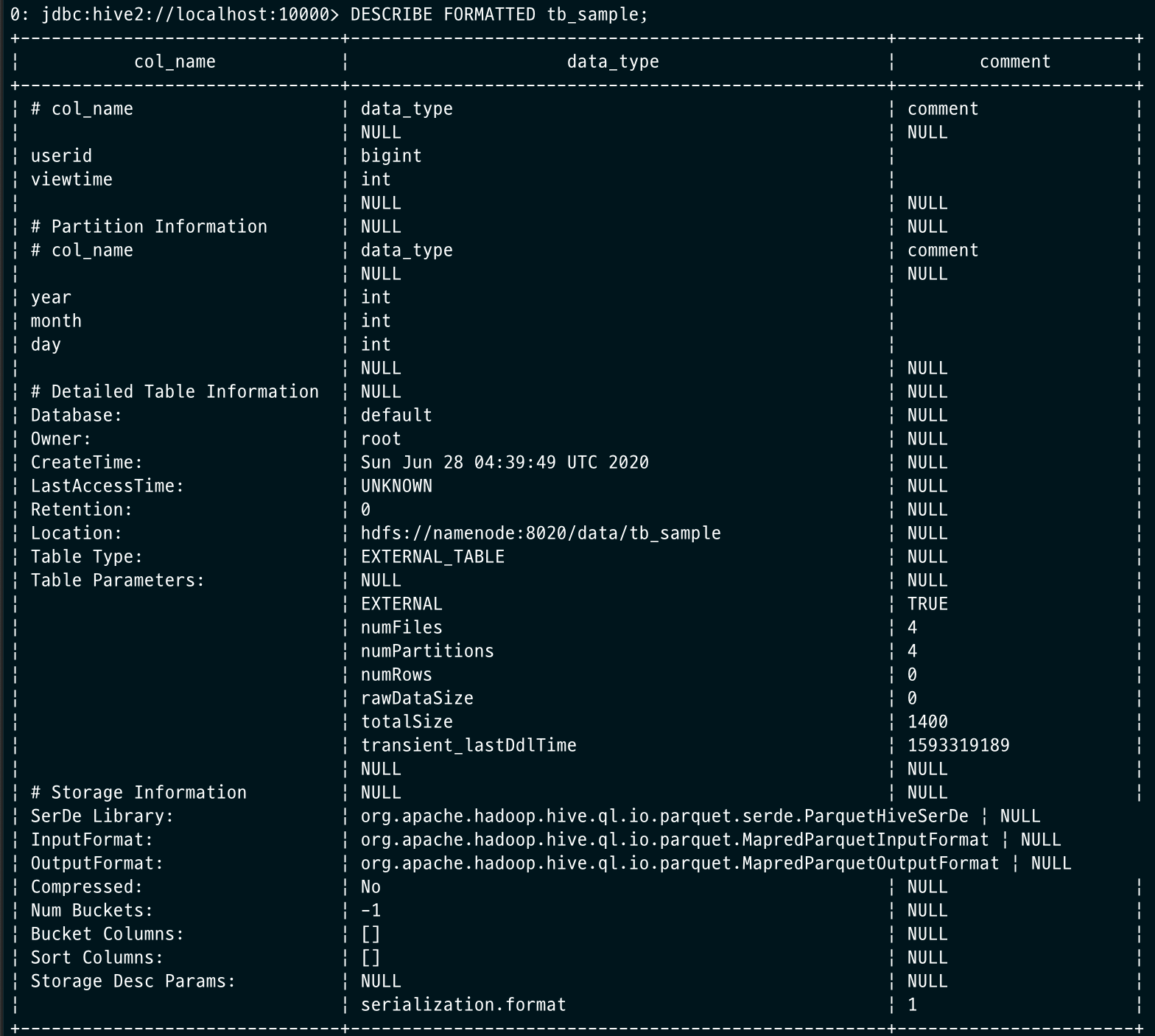
참고
Leave a comment