Spark Cluster Architecture와 Application Lifecycle
스파크 클러스터의 아키텍처와 스파크 어플리케이션 작업 흐름에 대해 정리해봅니다. 내가 제출한 작업이 스파크 클러스터에서 어떻게 시작되고 종료되는지 알아보고 싶은 분에게 추천합니다. 이번엔 코드는 없습니다.
스파크 클러스터 아키텍처
스파크는 대규모 데이터 처리 엔진입니다. 스파크는 하나의 컴퓨터로는 처리할 수 없는 대규모의 데이터를 처리하기 위해 여러 대의 컴퓨터를 묶은 클러스터에 작업을 제출할 수 있게 만들어졌습니다.
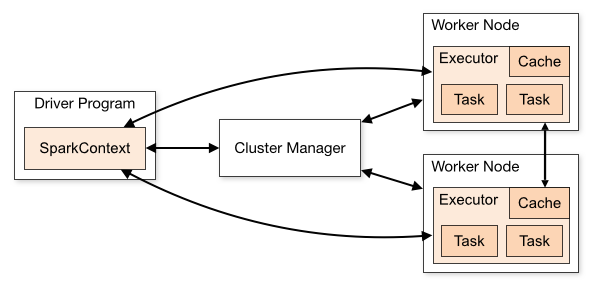
Spark의 클러스터 아키텍쳐에는 세가지 주요 요소가 있습니다. Cluster Manager, Driver Program, 그리고 Executor 입니다.
- Cluster Manager (클러스터 매니저)
- 스파크 클러스터를 유지하는 물리적인 클러스터 머신을 관리하는 서비스입니다.
- 클러스터 마스터와 클러스터 워커 노드로 구성됩니다.
- 다음과 같은 서비스로 cluster manager를 설정할 수 있습니다.
- Standalone (spark 자체 클러스터 매니저)
- Hadoop YARN
- Kubenetes
- Apahce Mesos (Deprecated 되었습니다.)
- Driver Program
- Spark Application의
main()함수를 실행하고SparkContext를 생성하는 프로세스 입니다. 스파크 드라이버 (Spark Driver) 라고도 합니다.
- Spark Application의
- Executor
- 워커노드에 실행되는 프로세스입니다. 드라이버의 요청을 받아서 task를 실행합니다.
클러스터당 하나의 클러스터 마스터, 어플리케이션당 하나의 Driver가 존재하게 됩니다. 개별 드라이버가 각 작업을 스케쥴링하고 서로 다른 어플리케이션과 격리됩니다. (서로 다른 어플리케이션의 task는 서로 다른 JVM에서 동작합니다.) 그래서 서로 다른 어플리케이션 간에는 외부 저장소에 데이터를 저장하지 않고서는 데이터 공유가 불가능합니다.
클러스터 매니저는 불과 몇년 전에는 Mesos와 YARN이 주력이었는데, 최근에는 Mesos가 탈락하고 Kubernetes가 급부상하는 모양입니다. K8s를 클러스터 매니저로 사용하면 서로 다른 버전의 스파크 어플리케이션을 하나의 클러스터에서 실행할 수 있다는 장점과 함께(의존성 관리에서 어느 정도 해방..?) K8s의 뛰어난 리소스 관리를 활용할 수 있습니다.
스파크 작업 흐름
스파크 어플리케이션의 시작부터 끝나는 과정을 정리하며 이해해봅니다.
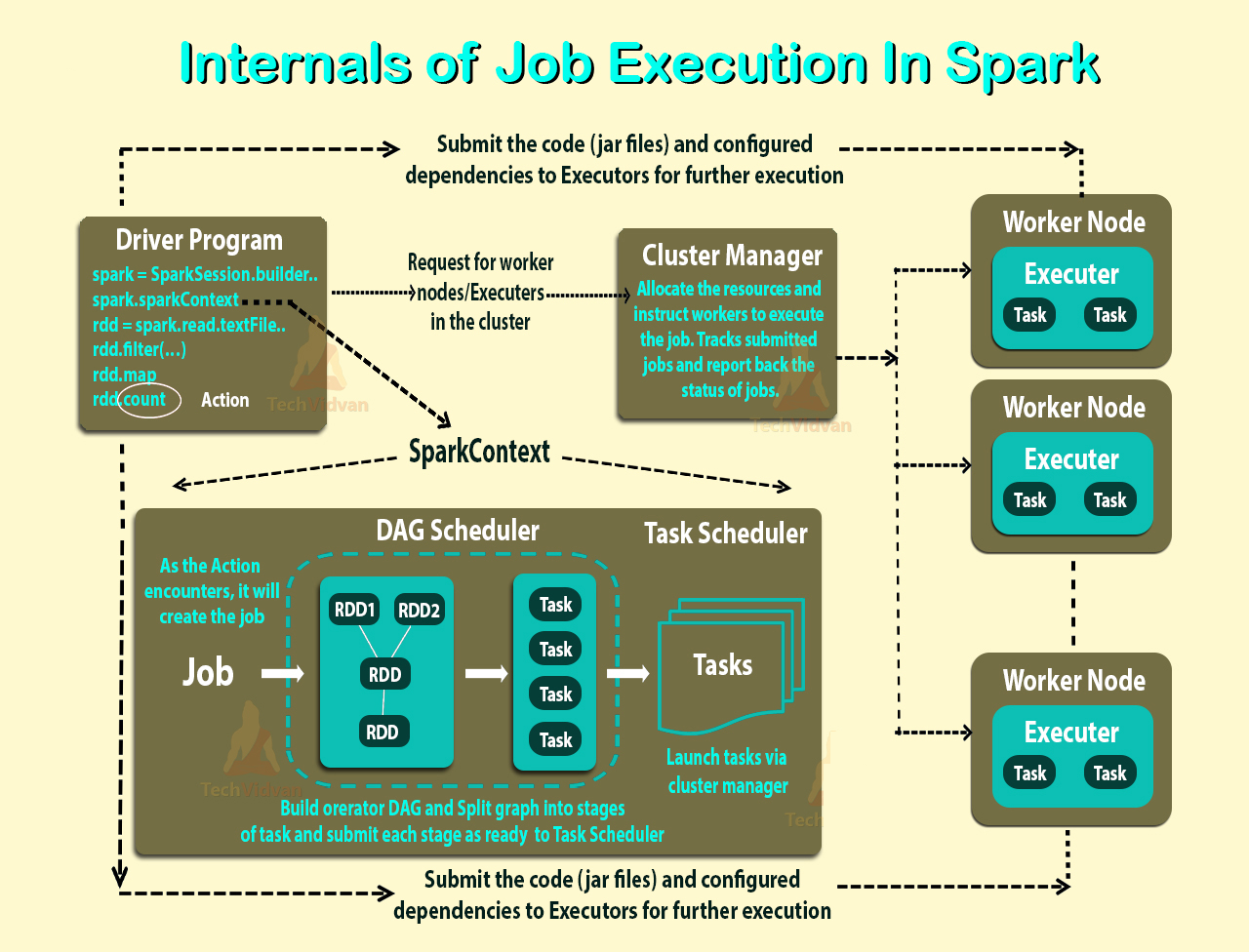
- spark-submit으로 클러스터에 스파크 애플리케이션이 제출되고나면, Driver Program의 main 함수에서
SparkContext가 생성되면서 스파크 작업이 시작됩니다. SparkContext를 통해 클러스터 매니저에게 애플리케이션을 실행할 리소스를 요청합니다.- 클러스터 매니저는 관리하는 워커 노드에 Executor를 실행하고 Driver가 사용할 수 있도록 할당합니다.
- 그러면 Driver가 Executor에게 작업할 내용인 Jar 혹은 Python code를 전달하고 실행할 Task를 전달합니다.
- Executor는 할당받은 계산을 실행하고 결과를 저장합니다.
- 작업 실행 도중 워커 노드에 문제가 생기면 Task는 다른 Executor에 전달되고 다시 실행됩니다.
- 작업이 끝나면 Executor가 종료되고 클러스터 매니저가 할당한 리소스를 회수합니다.
스파크 실행 모드
--deploy-mode 값을 cluster 혹은 client 로 주어서 실행 모드를 변경할 수 있습니다. 기본 값은 client 입니다. 여기서는 YARN을 기준으로 설명합니다.
- 클라이언트 모드
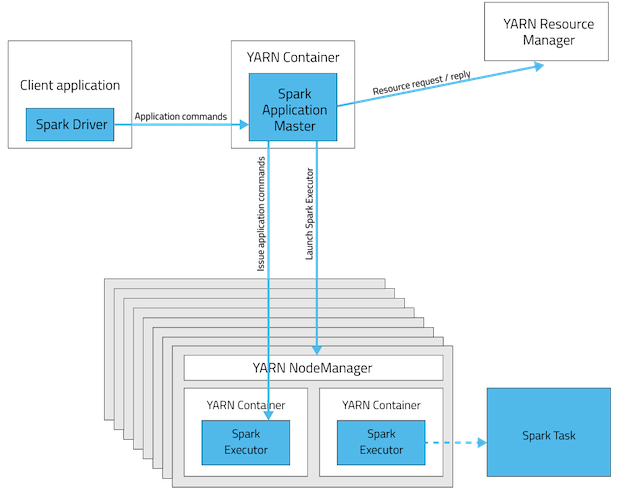
- 드라이버가 클라이언트 프로세스에서 실행됩니다.
- yarn은 마스터 노드를 관리하지 않고 executor 자원 분배하는 역할만 합니다.
- 대화형 쉘(spark-shell)을 지원하는 모드입니다.
- 클러스터 모드
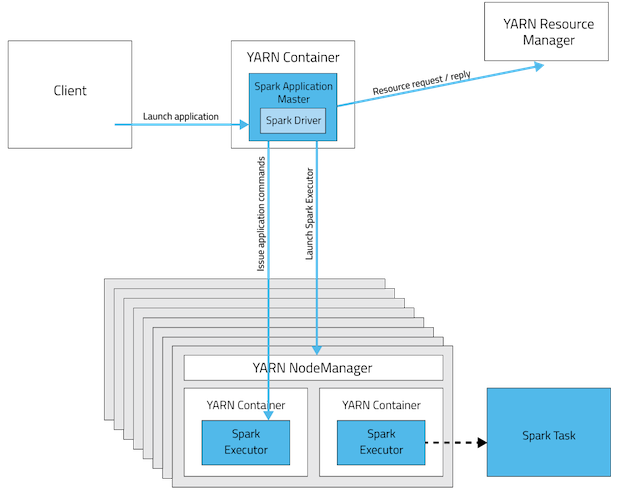
- 클라이언트는 애플리케이션을 생성 하고 즉시 종료됩니다.
- 클러스터 내부에 드라이버가 생성되고 YARN이 드라이버 프로세스를 관리합니다.
- local이나 laptop에서 외부 클러스터에 작업을 요청할 때는 cluster 모드를 사용하는 것이 권장됩니다. spark 작업은 driver와 executor가 지속해서 통신을 하는데, local에 띄워진 driver와 cluster에 있는 task가 서로 통신하면서 불필요한 network latency가 발생하기 때문입니다.
- spark app이 실행한 노드가 아닌 다른 노드에서 실행 될 수 있습니다.
- 그래서 라이브러리와 외부 jar 파일을 클러스터 노드에 수동 배포하거나, spark-submit 할 때
--jars인수 명시해서 배포해야합니다.
- 그래서 라이브러리와 외부 jar 파일을 클러스터 노드에 수동 배포하거나, spark-submit 할 때
참고 자료
읽어보면 더 좋습니다.
Leave a comment