spark-submit을 위한 스파크 앱 JAR 생성하기
Build scala Fat-Jar with SBT for spark-submit. SBT와 intelliJ를 이용해 scala spark 프로젝트를 fat-jar로 빌드하고, 잘 되었는지 spark-submit로 테스트 해봅니다.
완성된 코드는 Github: spark-fatJAR-example에서도 보실 수 있습니다.
Set project
새 스칼라 프로젝트를 생성합니다. 이 예제에서는 sbt로 진행합니다.
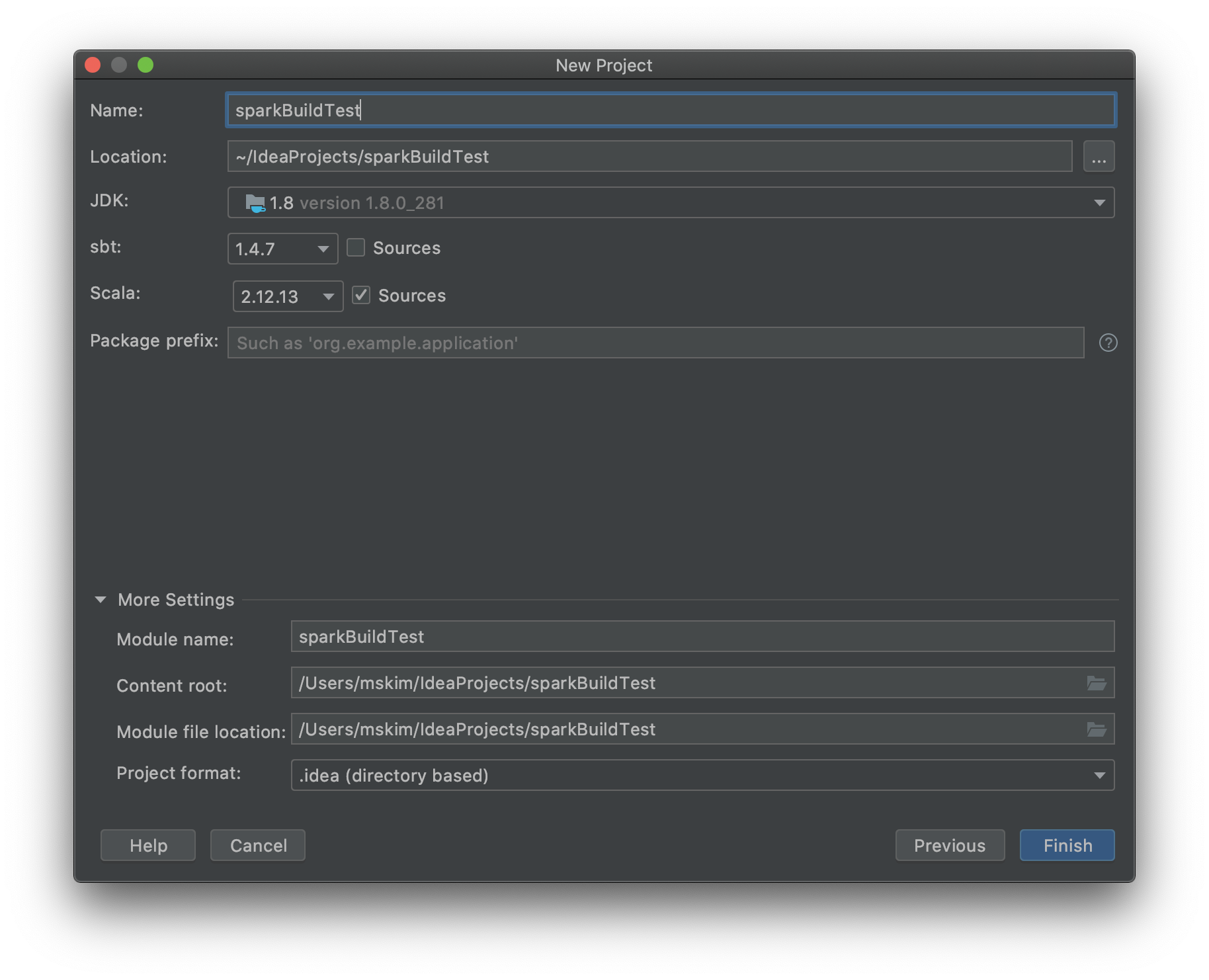
프로젝트 이름과 각 버전들을 명시해줍니다. spark 버전 3.1.1과 호환되는 scala 2.12.13 버전을 선택했습니다.
intelliJ에서 제공하는 plugins도 설치합니다.
이제 세팅된 프로젝트 아래의 파일 세 개만 변경하면 되겠습니다.
.
├── build.sbt # <-- 1
├── project
│ ├── build.properties
│ ├── plugins.sbt # <-- 2 처음에는 없습니다!
│ ├── project
│ └── target
├── src
│ ├── main # <-- 3
│ └── test
└── target
├── global-logging
├── scala-2.12 # <-- 여기에 jar가 생성됩니다.
├── streams
└── task-temp-directory
build.sbt
버전, 환경세팅 관련해서 여기에 정의해줍니다.
// build.sbt
lazy val commonSettings = Seq(
name := "spark-fatJAR-example",
version := "1.0",
scalaVersion := "2.12.13"
)
lazy val app = (project in file(".")).
settings(commonSettings: _*)
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-sql" % "3.1.1"
)
// 재빌드 시에 사용됨
assemblyMergeStrategy in assembly := {
case PathList("META-INF", xs @ _*) => MergeStrategy.discard
case x => MergeStrategy.first
}
sbt 파일을 수정하면 project structure가 수정되었다면서 다시 load 하라고 할 겁니다. intelliJ가 시키는 대로 하면 됩니다.
plugin.sbt
fat-jar 를 위한 sbt-assembly 플러그인 파일을 명시해줍니다.
addSbtPlugin(
"com.eed3si9n" % "sbt-assembly" % "0.15.0"
)
src/main/scala
.
├── main
│ └── scala
│ └── buildExample
│ └── helloworld.scala
└── test
└── scala
src/main/scala 아래 buildExample 패키지를 만들고 scala object 파일을 만들었습니다. 패키지가 없으면 jar로 만들었을 때 클래스를 못 찾더라고요. 왜 그런지는 더 찾아봐야겠습니다.
// helloworld.scala
package buildExample
import org.apache.spark.sql.SparkSession
object helloworld {
def main(args: Array[String]): Unit = {
println("Hello, Spark!")
val logFile = "README.md" // Should be some file on your system
val spark = SparkSession.builder.appName("helloWorld").getOrCreate()
val logData = spark.read.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
spark.stop()
}
Hello, Spark! 프린트를 찍고나서 readme 파일의 a, b가 포함된 라인을 세는 간단한 예제입니다.
with docker container [cf.]
찾아보니 역시 scala-sbt가 설치된 이미지가 있더군요. github.com/hseeberger/scala-sbt 그런데 ide로 하는 것보다 느린 것 같은 느낌적인 느낌..
docker run -it --rm --name scala \
-u sbtuser \
--mount type=bind,source="$(pwd)"/scala,target=/home/sbtuser \
hseeberger/scala-sbt:graalvm-ce-21.0.0-java8_1.4.9_2.12.13 \
/bin/bash
도커 컨테이너를 사용할 때는 root 유저로 들어가지 않도록 합시다. 참고
Build Jar
이제 준비가 끝났습니다.
찾아보니 다른 빌드하는 방법이 여러가지던데, 각각 비교해서 따로 정리해보면 좋을 것 같습니다. 정리가 되면 본 글에 링크를 추가하도록 하겠습니다.
sbt assembly
assemble!
sbt assembly
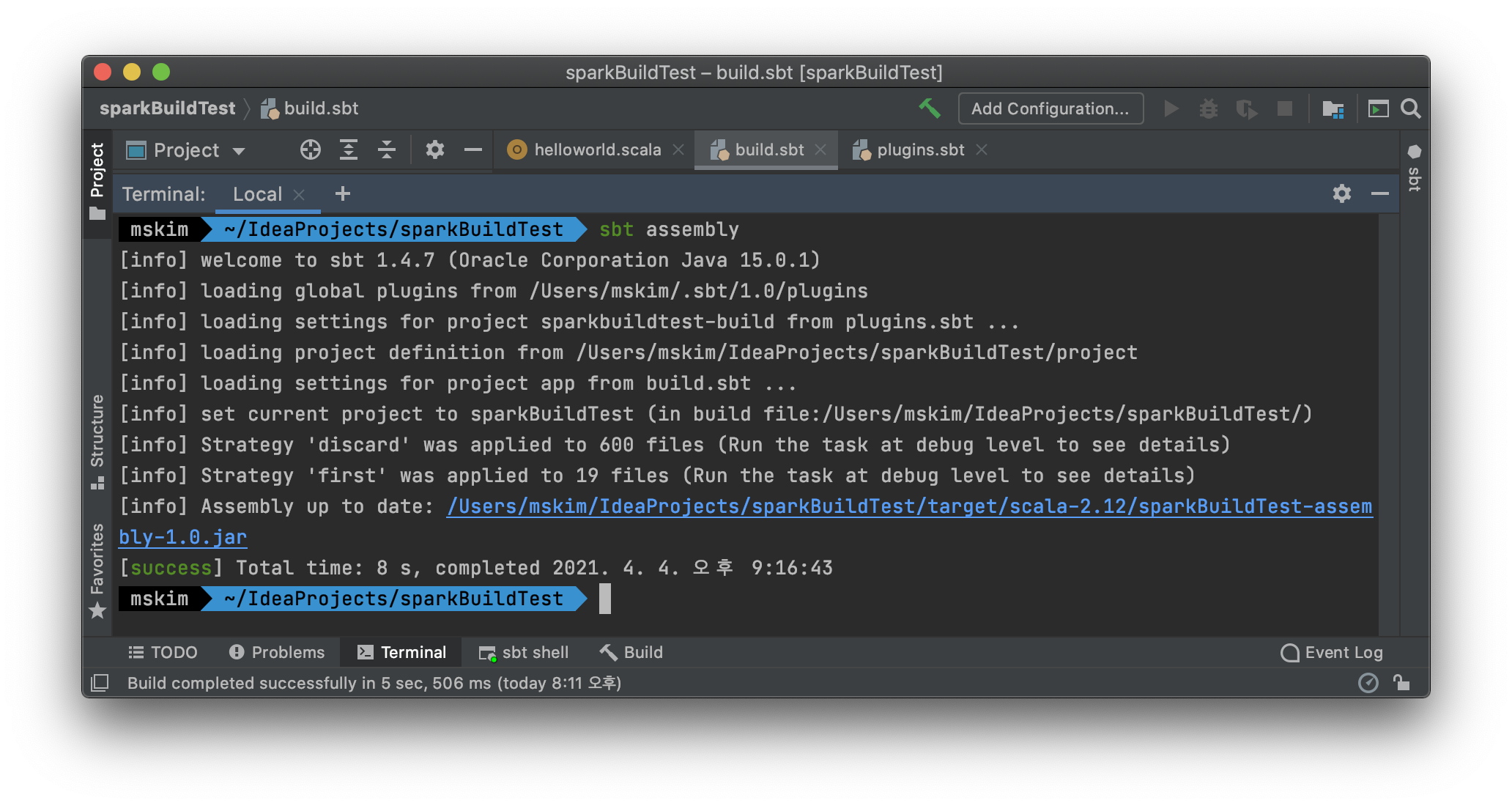
빌드가 완료되면 스크린샷의 링크 위치에 assembly-jar가 생성됩니다. 저는 처음 생성한 것이 아니라서 up to date 되었다고 나오네요. jar 파일은 target/scala 경로 아래에 생깁니다.
Test Jar
만들어진 Jar 파일이 스파크에서 잘 돌아가는지 실행해봅니다.
spark-submit
워커 2대, 마스터 1대로 구성된 컨테이너로 테스트했습니다.
# deploy spark cluster
$ docker-compose up -d # yaml 파일은 깃 참조!
# file copy from local to container
$ docker cp target/scala-2.12/spark-fatJAR-example-assembly-1.0.jar spark-fatjar-example_spark_1:/opt/bitnami/spark/work
# spark-submit (check master IP)
$ docker-compose exec spark ./bin/spark-submit \
--class buildExample.helloworld \
--master spark://4f20d2739c84:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
work/spark-fatJAR-example-assembly-1.0.jar
"""
21/04/04 11:26:02 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Hello, Spark!
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/04/04 11:26:03 INFO SparkContext: Running Spark version 3.1.1
21/04/04 11:26:03 INFO ResourceUtils: ==============================================================
21/04/04 11:26:03 INFO ResourceUtils: No custom resources configured for spark.driver.
21/04/04 11:26:03 INFO ResourceUtils: ==============================================================
21/04/04 11:26:03 INFO SparkContext: Submitted application: buildTest helloworld
...
...
21/04/04 11:26:40 INFO TaskSchedulerImpl: Killing all running tasks in stage 3: Stage finished
21/04/04 11:26:40 INFO DAGScheduler: Job 1 finished: count at helloworld.scala:12, took 0.345741 s
Lines with a: 64, Lines with b: 32
...
"""
Hello, Spark! 를 프린트하고 마지막 부분에 Lines with a: 64, Lines with b: 32를 프린트합니다.
closing
일단은 scala-spark-jar 빌드 글을 이렇게 마무리합니다. 다만, 글을 쓰면서 미처 다루지 못한 부분들이 많이 보여 추가로 글을 쓰게 될 것 같습니다. 스파크에서 돌아가는 jar 파일을 만들어보겠다고 삽질하느라 이해 안하고 넘긴 부분이 꽤나 되서.. sbt 파일도 하나하나 다시 공부하면서 찾아봐야겠습니다. 다른 분들은 일단 여기까지는 쉽게 오시길!
- 2021-04-19: git repo에 코드를 추가했습니다.
참고
Leave a comment