Data ETL with Spark (Spark로 데이터 처리하기)
모든 데이터 작업의 시작이자 끝인 ETL! 스파크를 이용하여 파일을 읽고, 변형하여 저장하는 방법에 대해 소개합니다. 데이터는 Kaggle의 Suicide Rates Overview 1985 to 2016를 사용했습니다.
스칼라 기준으로 작성하였습니다만, DataFrame API는 scala와 python의 명령어가 동일합니다. 제플린에서 pyspark를 사용하시려면 paragraph 상단에 %pyspark를 붙여주세요. Pyspark 참고 환경 구성은 제플린/스파크 도커로 설치하기를 참고하시면 좋습니다.
추천 독자: 일단 사용하면서 스파크를 익히고 싶으신 분.
Intro
전체 흐름입니다.
//scala
import org.apache.spark.sql.Encoders
import org.apache.spark.sql.functions._
case class DataSuicides (
country: String
, year: String
, sex: String
, age: String
, suicides_no: Float
)
// read
var df = spark.read
.option("header", "true")
.schema(Encoders.product[DataSuicides].schema)
.csv("/data/master.csv")
// transform
df = df.withColumn("constant_1", lit(1))
.withColumn("id", monotonically_increasing_id())
df.createOrReplaceTempView("df")
val sui_per_year = sql("""
select year
, sum(suicides_no) sum_sui
, round(avg(suicides_no), 1) avg_sui
from df
group by year
order by 1
limit 3
""")
// write
sui_per_year
.coalesce(1)
.write.mode("overwrite")
.parquet("/data/sui_per_year")
전체 흐름은 간단히 작성하였습니다. 그럼 이제 하나씩 자세히 보겠습니다.
Spark Read CSV, JSON, Parquet
스파크 쉘 등을 실행하면 스파크 세션이 생성되며 spark 변수로 사용할 수 있습니다.
아래와 같은 방식으로 불러오면 DataFrame이라는 구조적 API를 반환하게 됩니다.
로우와 컬럼으로 정의된 테이블이며, 간단하게 엑셀 시트라고 생각하셔도 무방합니다.
pandas 데이터프레임으로도 손쉽게 바꿀 수 있습니다.
// 축약형
var df = spark.read
.option("header", "true")
.csv("/data/master.csv") // .json(filepath), .parquet(filepath)
.select("country", "year", "sex", "age", "suicides_no") // 일부 컬럼만 로드
// 기본형
// var df = spark.read
// .format("csv") // json, parquet
// .load("/data/master.csv")
df.show(3)
df.printSchema() // 컬럼 스키마를 보여줍니다.
/* OUTPUT
+-------+----+------+-----------+-----------+
|country|year| sex| age|suicides_no|
+-------+----+------+-----------+-----------+
|Albania|1987| male|15-24 years| 21|
|Albania|1987| male|35-54 years| 16|
|Albania|1987|female|15-24 years| 14|
+-------+----+------+-----------+-----------+
only showing top 3 rows
root
|-- country: string (nullable = true)
|-- year: string (nullable = true)
|-- sex: string (nullable = true)
|-- age: string (nullable = true)
|-- suicides_no: string (nullable = true)
*/
예제로는 csv를 사용했지만 json과 parquet도 동일하게 사용하시면 됩니다.
읽기 모드
항상 예상한 대로 데이터가 들어오지는 않습니다. 예를 들어, 컬럼이 하나 덜 들어올 수도 있고, 구분자 혹은 문자열의 인코딩이 다르거나, 들어오지 않던 헤더(컬럼명)가 입수되는 경우 등등이 있습니다. (생각보다 자주, 더 다양하게..) 이처럼 기존에 설정한 형식에 맞지 않는 데이터가 입수되는 경우를 대처하기 위해 읽기 모드를 설정할 수 있습니다.
| 읽기 모드 | 동작 |
|---|---|
| permissive (default) | 오류 레코드를 모두 null로 설정하고 해당 라인을 _corrupt_record 문자열 컬럼에 표시합니다. |
| dropMalformed | 형식에 맞지 않는 로우를 제거합니다. (무시) |
| failFast | 형식에 맞지 않는 로우를 만나면 종료합니다. (에러발생) |
위에 있는 OUTPUT을 보시면 모든 컬럼의 타입이 String인 것을 확인할 수 있습니다. 타입이 중요하지 않은 경우에는 상관 없지만,
엄격한 형식 관리가 필요할 때는 데이터 스키마를 지정해두고, 읽기 모드를 failFast 등으로 설정하여 뭔가 이상하다 싶으면 에러가 뜨게 만들 수 있습니다.
서비스가 중단되면 안 되거나 어느 정도 유실되어도 괜찮은 데이터라면 dropMalformed를 사용할 수도 있겠죠.
스키마
형식에 맞지 않는 경우에 어떻게 해라,라고 하려면 일단 우리가 원하는 형식을 지정해주어야겠죠.
아래 방법은 스칼라의 case class를 이용하는 방법입니다.
Spark의 StructType과 StructField를 사용하는 방법도 있지만, 저는 이 방법의 코드가 더 깔끔한 것 같습니다.
case class
import org.apache.spark.sql.Encoders
case class DataSuicides (
country: String
, year: String
, sex: Float // 일부러 틀린 형식을 전달해보겠습니다.
, age: String
, suicides_no: Float
, _corrupt_record: String // 오류 데이터를 확인하기 위한 추가 컬럼이 필요합니다.
)
// read
var df = spark.read
.option("header", "true")
.schema(Encoders.product[DataSuicides].schema)
// spark encoder로 만들어 둔 클래스를 변환합니다.
.csv("/data/master.csv")
df.show(3)
/* OUTPUT
+-------+----+----+----+-----------+--------------------+
|country|year| sex| age|suicides_no| _corrupt_record|
+-------+----+----+----+-----------+--------------------+
| null|null|null|null| null|Albania,1987,male...|
| null|null|null|null| null|Albania,1987,male...|
| null|null|null|null| null|Albania,1987,fema...|
+-------+----+----+----+-----------+--------------------+
only showing top 3 rows
*/
permissive 모드에서 오류 레코드가 들어온 경우 예시
(스파크 2.3미만 버전에서는 제대로 동작하지 않을 수 있습니다.)
inferSchema
스파크가 타입을 추론하도록 하는 옵션인 .option("inferSchema", "true")을 사용할 수도 있습니다.
var df = spark.read
.option("header", "true")
.option("inferSchema", "true")
.csv("/data/master.csv")
df.printSchema()
/* OUPUT
root
|-- country: string (nullable = true)
|-- year: integer (nullable = true)
|-- sex: string (nullable = true)
|-- age: string (nullable = true)
|-- suicides_no: integer (nullable = true)
|-- population: integer (nullable = true)
|-- suicides/100k pop: double (nullable = true)
|-- country-year: string (nullable = true)
|-- HDI for year: double (nullable = true)
|-- gdp_for_year ($) : string (nullable = true)
|-- gdp_per_capita ($): integer (nullable = true)
|-- generation: string (nullable = true)
*/
inferSchema 옵션 True 적용 시
읽기 옵션
상황에 따라 다양한 형태의 데이터를 마주하게 되는데, .option()을 추가하여 원하는 형식으로 불러올 수 있습니다. 특히 한국어 데이터의 경우 인코딩 확인 필수. 옵션의 파라미터를 잘못 넣어주게 되면 오류가 나는게 아니라 무시가 되기 때문에 오타를 잘 확인해야합니다.
//scala
val dataCsv = spark.read
.option("mode", "FAILFAST")
.option("header","true") // default: false
.option("charset","euc-kr") // default: utf-8
.option("sep","|") // default: , Comma Seperated Value!
//.option("codec","gzip") // bzip2, gzip, l4 and snappy 지원
.csv("/data/csv/path")
더 많은 옵션은 databricks - data-sources 에서 확인할 수 있습니다.
zeppelin 버전에 따라 .option 의 .을 뒤에 붙여야 하는 경우가 있습니다. 환경설정으로 허용 여부를 바꿀 수 있습니다.
Spark Transform DataFrame
변형은 쓰다 보면 한도 끝도 없이 길어질 수 있기 때문에 이번 포스트에서는 간단하게 작성했습니다.
컬럼 추가
withColumn 을 통해서 컬럼을 추가할 수 있습니다.
import org.apache.spark.sql.functions.{monotonically_increasing_id, lit}
df = df.withColumn("constant_1", lit(1))
.withColumn("id", monotonically_increasing_id()) // 1 to rownum 보장하지 않음
명시적인 값을 넣어주고 싶다면 literal의 약자인 lit을 사용하시면 됩니다.
Continuous Index
monotonically_increasing_id와 함께 사용하면 로우마다 유니크한 값을 달아줄 수 있습니다.
다만 1부터 rownum까지의 연속성은 보장하지 않습니다.
1, 2, 3, 4… 하다가 100000001 이런 식으로 간격이 벌어지는데, 서로 다른 노드에서 작업하는 스파크 특성상 어쩔 수 없다고 합니다.
연속성을 보장하려면 rdd와 함께 쓰는 zipWithIndex 혹은 Window를 사용할 수 있지만 성능상 이슈가 있을 것 같네요.
애초에 연속성 보장이 꼭 필요하다면 성능 이슈가 있어도 어쩔 수 없겠죠.
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.StructField
// with rdd
val withRddIndexDF = spark.sqlContext.createDataFrame(
df.rdd.zipWithIndex.map{
case (row, idx) => Row.fromSeq(row.toSeq:+ idx)
}, StructType(df.schema.fields :+ StructField("index", LongType, false)))
// with window: 컬럼 하나를 기준으로 정렬하는 방법도 있답니다.
import org.apache.spark.sql.expressions.Window
val w = Window.orderBy("colunm")
val withWindowIndexDF = df.withColumn("idx", row_number().over(w))
RDD는 DataFrame API보다 저수준의 API입니다. DataFrame을 사용하면 RDD로 컴파일되고 최적화되어 효율적으로 돌아가기 때문에 위와 같이 특별한 이유가 없다면 DataFrame을 사용하는 것이 좋습니다. 물론 스파크가 어떻게 돌아가는지 깊게 알아보고자 한다면 꼭 알아둬야겠습니다. (저도 기회가 된다면…)
컬럼명 변경
var df = spark.read.option("header", "true")
.csv("/data/master.csv")
.select("year", "gdp_per_capita ($)") // sql 명령어와 매우 유사합니다.
/*
+----+------------------+
|year|gdp_per_capita ($)|
+----+------------------+
|1987| 796|
|1987| 796|
+----+------------------+*/
df = df.withColumnRenamed("gdp_per_capita ($)", "gdp_per_cap")
/*
+----+-----------+
|year|gdp_per_cap|
+----+-----------+
|1987| 796|
|1987| 796|
+----+-----------+*/
원 데이터에 특수문자와 공백이 포함된 컬럼(gdp_per_capita ($))이 있는데 이런 부분이 장애를 일으키는 원인이 될 수 있습니다.
withColumnRenamed로 바꿔줄 수 있습니다.
df = spark.read
.csv("/data/master.csv")
.select("_c0", "_c1") // 헤더가 없는 경우의 기본 컬럼명 형식
.toDF("c", "y")
/*
+-------+----+
| c| y|
+-------+----+
|country|year|
|Albania|1987|
|Albania|1987|
+-------+----+*/
애초에 불러올 때 .toDF로 컬럼명을 overwrite 해서 가져올 수도 있습니다.
with SparkSQL
위에서 이미 느끼셨겠지만, SQL에 익숙하신 분들은 스파크 사용하기가 굉장히 수월합니다.
groupby를 해보겠습니다.
df.groupBy("year").agg(
sum("suicides_no").alias("sum_sui")
, expr("round(avg(suicides_no), 1)").alias("avg_sui"))
.orderBy(desc("year")).limit(3)
.show()
/*
+----+--------+-------+
|year| sum_sui|avg_sui|
+----+--------+-------+
|2016| 15603.0| 97.5|
|2015|203640.0| 273.7|
|2014|222984.0| 238.2|
+----+--------+-------+*/
어떤가요? 사실 저는 주로 아래처럼 사용합니다.
df.createOrReplaceTempView("df")
val sui_per_year = sql("""
select year
, sum(suicides_no) sum_sui
, round(avg(suicides_no), 1) avg_sui
from df
group by year
order by 1
limit 3
""")
sui_per_year.show()
/*
+----+--------+-------+
|year| sum_sui|avg_sui|
+----+--------+-------+
|1985|116063.0| 201.5|
|1986|120670.0| 209.5|
|1987|126842.0| 195.7|
+----+--------+-------+
sui_per_year: org.apache.spark.sql.DataFrame = [year: string, sum_sui: double ... 1 more field]*/
굉장히 친숙하지 않습니까. 스파크의 가장 큰 장점이 아닌가 싶습니다. 스파크 SQL은 하이브와도 잘 연동이 됩니다.
다만 OLTP(online transaction processing)가 아닌 OLAP(online analytic processing), 즉 분석용 DB로 동작합니다. 게다가 현재까지는 UPDATE라는 개념 자체도 없습니다. 스파크의 RDD 동작 특성상 쉽진 않겠다 싶긴 한데, RDD에 대해 나중에 꼭 정리하긴 해야겠습니다. 문자열로 표현하다 보니 syntax표시가 되지 않는 것도 아쉽긴 합니다.
Delta Lake - Azure Databricks 소개 databricks에서 spark api와 호환되면서 update까지 지원하는 delta lake라는 걸 내놓긴 했네요.
게다가 위처럼 createOrReplaceTempView로 선언한 테이블은 제플린에서 %sql로 쉽게 조회가 가능하고, 다양한 형식으로 시각화가 가능합니다.
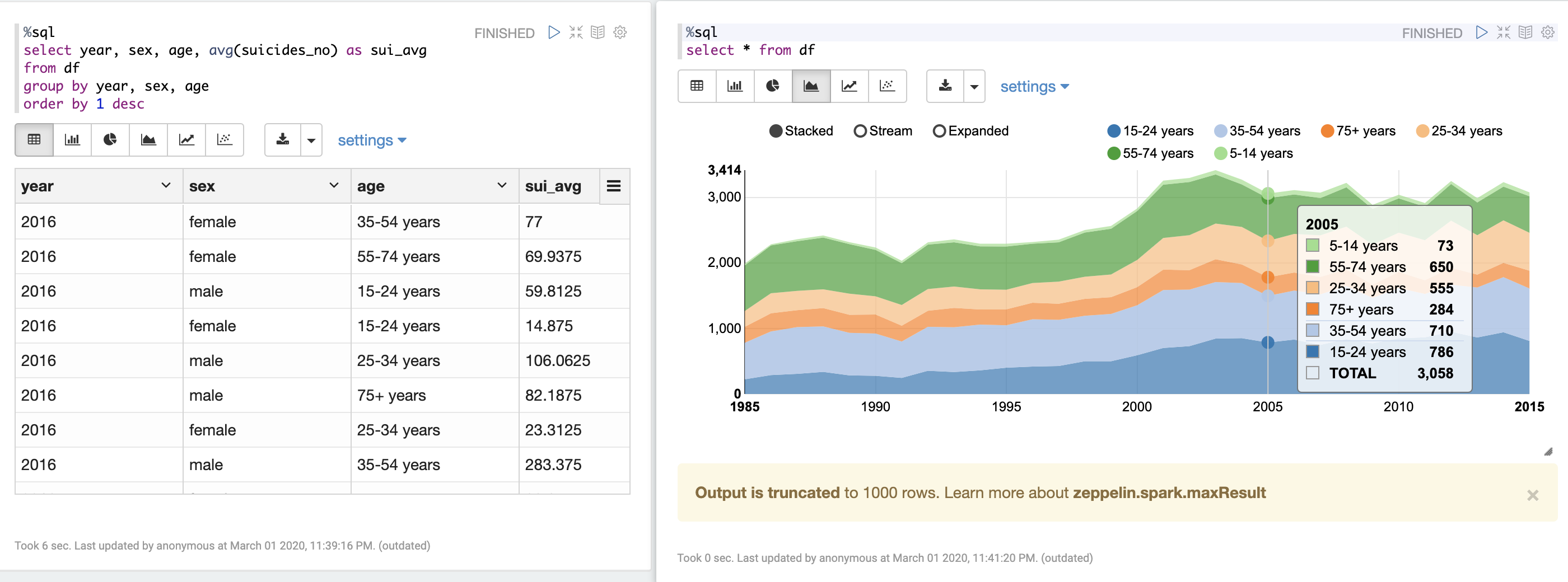 반응형입니다. 간단하게 사용하기 좋아요.
반응형입니다. 간단하게 사용하기 좋아요.
with Pandas
스파크의 DataFrame은 Pandas로 쉽게 변경이 가능합니다. 하지만 1개의 노드에 모든 데이터가 합쳐지기 때문에 대용량 작업을 하던 상황이었다면 많은 부하가 발생할 수 있습니다.
%pyspark
df = spark.read \
.option("header", "true") \
.csv("/data/master.csv") \
.select("country", "year", "sex", "age", "suicides_no")
df.show(3)
a = df.toPandas()
print(type(a))
# +-------+----+------+-----------+-----------+
# |country|year| sex| age|suicides_no|
# +-------+----+------+-----------+-----------+
# |Albania|1987| male|15-24 years| 21|
# |Albania|1987| male|35-54 years| 16|
# |Albania|1987|female|15-24 years| 14|
# +-------+----+------+-----------+-----------+
# only showing top 3 rows
#
# <class 'pandas.core.frame.DataFrame'>
Spark Write CSV, JSON, Parquet
작업한 결과물을 파일로 써보겠습니다.
sui_per_year.coalesce(1)
.write.mode("overwrite")
.option("header", "true")
.option("sep", "|")
.option("encoding", "euc-kr")
.option("codec", "gzip")
.csv("/data/sui_per_year")
아주 간단하게 결과물을 저장했습니다. read와 마찬가지로 다양한 옵션을 적용할 수 있습니다.
Parquet
스파크는 분산 처리를 위해 각 노드에 원본 데이터를 옮겨야 하기 때문에 특히 큰 데이터의 경우 압축 여부에 따라 성능 차이가 많이 나게 됩니다. Parquet는 snappy라는 압축 형식으로 저장하는 것이 기본값이고, 컬럼 정보도 함께 저장되기 때문에 다른 이유가 없다면 Parquet를 사용하는 것을 추천합니다. 게다가 JSON처럼 계층형 정보도 저장이 가능합니다. 다만 일반적인 텍스트 에디터에서 Raw 데이터를 확인할 수가 없다는 단점이 있습니다.
그래도 parquet 좋습니다. 빠르고, csv처럼 option 이것저것 신경 쓸 필요가 없습니다.
coalesce, repartition
분산처리를 하는 스파크는 알아서 쓰게 내버려 둘 경우 각 작업 노드가 지정 경로에 하나씩 파일을 떨구게 됩니다. 데이터 크기가 작아서 노드 하나에서 작업하고 있었다면 그냥 파일 하나가 생성됩니다. 그런데 데이터를 요청한 사람에게 용량 1MB짜리 파일 20개씩 전달하면 당황하겠죠? 그럴 때 데이터를 지정한 수로 병합하는 .coalesce()를 사용하면 됩니다. 가령 20개의 노드에서 작업하던 것을 지정한 수의 노드에게 할당해서 작업하게 하는 것이죠.

이것이 분산처리 시스템이다
coalesce와 유사한 기능을 하는 repartition도 있는데, 얘는 전체 데이터를 셔플하기 때문에 더 작은 파티션 수로 줄일 때는 셔플이 일어나지 않는 coalesce를 사용하는 것이 좋습니다.
그럼 repartition은 언제 쓰냐 하시면, 얘는 자주 사용하는 컬럼을 기준으로 데이터를 물리적으로 재분배하는 것이기 때문에 성능을 최적화할 때 사용하면 된다고 합니다. 향후 사용할 파티션 수를 늘릴 경우 혹은 컬럼 기준으로 파티션을 만드는 경우라고 합니다. 혹은 데이터를 한번 섞어서 골고루 저장되도록 할 수도 있겠죠? 저도 아직 이걸 쓸 정도로 성능을 끌어올려 본 적이 없네요.
블록 파편화
파티션에 더불어 하나 더 말씀드리자면, Spark와 HDFS를 함께 사용하는 경우가 많은데, 하둡은 각 데이터를 블록 단위로 저장합니다. 그리고 스파크로 작업을 하다 보면 위 이미지처럼 잘게 쪼개진 파일의 수가 굉장히 늘어날 수가 있는데, 이런 경우에도 하둡은 각 파일마다 일정한 크기의 블록을 할당하게 되고 결국 파일 총량에 비해 블록 수가 과다하게 많아져서 하둡 시스템에 부하를 줄 수가 있습니다. OS - Memory - 내부 단편화가 오버랩됩니다. 그러니 결과 데이터가 작을 때는 꼭 coalesce를 잊지 말고 사용합시다. 물론 충분히 큰 데이터를 다루고 있다면(그리고 특별히 다른 이유가 없다면) 굳이 파일을 하나로 합쳐 놓을 필요가 없습니다. 미리 나누어져 있으면 여러 노드가 읽을 때 성능상 유리하겠죠?
일단 임시 경로에 write 하시고, 여러 개로 쪼개진 파일을 다시 불러와 병합만 하는 것이 작업 시간 단축에 도움이 됩니다. 동일 경로에 덮어쓰려고 하면 에러납니다.
Outro
첫 전체 흐름에 비해서 이것저것 많이 추가하게 된 것 같습니다. 사실 파일 읽고 tempView 생성해서 쿼리 날리듯이 변형하고, 결과 저장하면 데이터 작업 중 대략 80% 정도는 처리할 수 있지 않을까요? (너무 많나요?) 아무튼 나머지 20%를 채우기 위해 다음 포스트도 힘내서 써보겠습니다.
Leave a comment