Machine Learning with Spark (Spark로 머신러닝하기)
스파크의 분산처리 능력을 머신러닝에 사용할 수 있습니다. 간단한 자연어 처리 예제와 함께 알아보겠습니다. 비교적 쉽게 접할 수 있는 scikit-learn, R, tensorflow와 달리 SparkML은 흔치 않지만, 나름대로의 장점이 있습니다.
추천 독자:
- 대량의 데이터 처리를 위한 기계 학습 프로세스가 필요한 분
- 자연어 처리 프로세스를 간단하게 알아보고 싶은 분
Intro
SparkML
SparkML도 다른 머신러닝 라이브러리들과 마찬가지로 학습을 위한 전처리, 모델 알고리즘, 성능을 극대화하기 위한 도구들을 지원합니다. 다만, 다른 라이브러리에 비해 스파크는 대중적으로 사용되는 몇몇 알고리즘만 구현되어 있습니다. 새롭거나 핫한 모델이 나와도 스파크에서 쓰려면 다른 라이브러리보다는 조금 더 기다려야 합니다.
그럼 SparkML을 왜 쓸까요? 대량의 데이터를 처리하는데 매우 적합하기 때문입니다. 데이터의 수는 갈수록 늘어나고 있고 단일 머신에서 데이터를 처리하기에는 분명 한계가 있습니다. 전처리 돌려놓고 한참 다른 일하고 와도 여전히 돌고 있는 주피터 노트북을 보고 나면 가슴이 답답해지지 않나요? 스파크를 쓰면 시간을 아낄 수 있습니다.
학습에 필요한 전처리를 스파크로 진행하고 모델링은 텐서플로우와 같은 타 라이브러리로 진행하거나, 스파크 지원 모델로 충분한 프로젝트라면 모델링까지 스파크로 마무리하여 작업의 속도를 높일 수 있습니다.
| SparkML | scikit-learn, Tensorflow, Torch | |
|---|---|---|
| 장점 | 확장성 | 업데이트 주기, 실시간 예측, 배포 |
SparkML은 대체재가 아닌 보완재로 사용하면 좋습니다.
스파크에는 ml 패키지와 mllib 패키지가 존재하는데, 두 패키지는 DataFrame과 RDD의 관계와 유사합니다. 저수준의 RDD API와 이를 위한 mllib은 현재 아파치 스파크 내에서 유지보수 모드(새로운 기능 추가 없이 버그만 수정)라고 합니다. 따라서 특별한 이유가 없다면 spark.ml과 DataFrame을 사용합시다.
Example
크롤링해서 모아둔 게임 리뷰 데이터를 활용해서 유저의 리뷰가 긍정적인지, 부정적인지 분류하는 모델을 만들어 보겠습니다.
데이터는 게임명, 평가한 유저, 유저의 게임 평가 점수(0부터 10까지), 그리고 리뷰로 되어있습니다. 총 62,415개의 리뷰입니다. 빅-데이터는 아니지만 예제로 쓰기엔 충분한 숫자일 듯합니다.
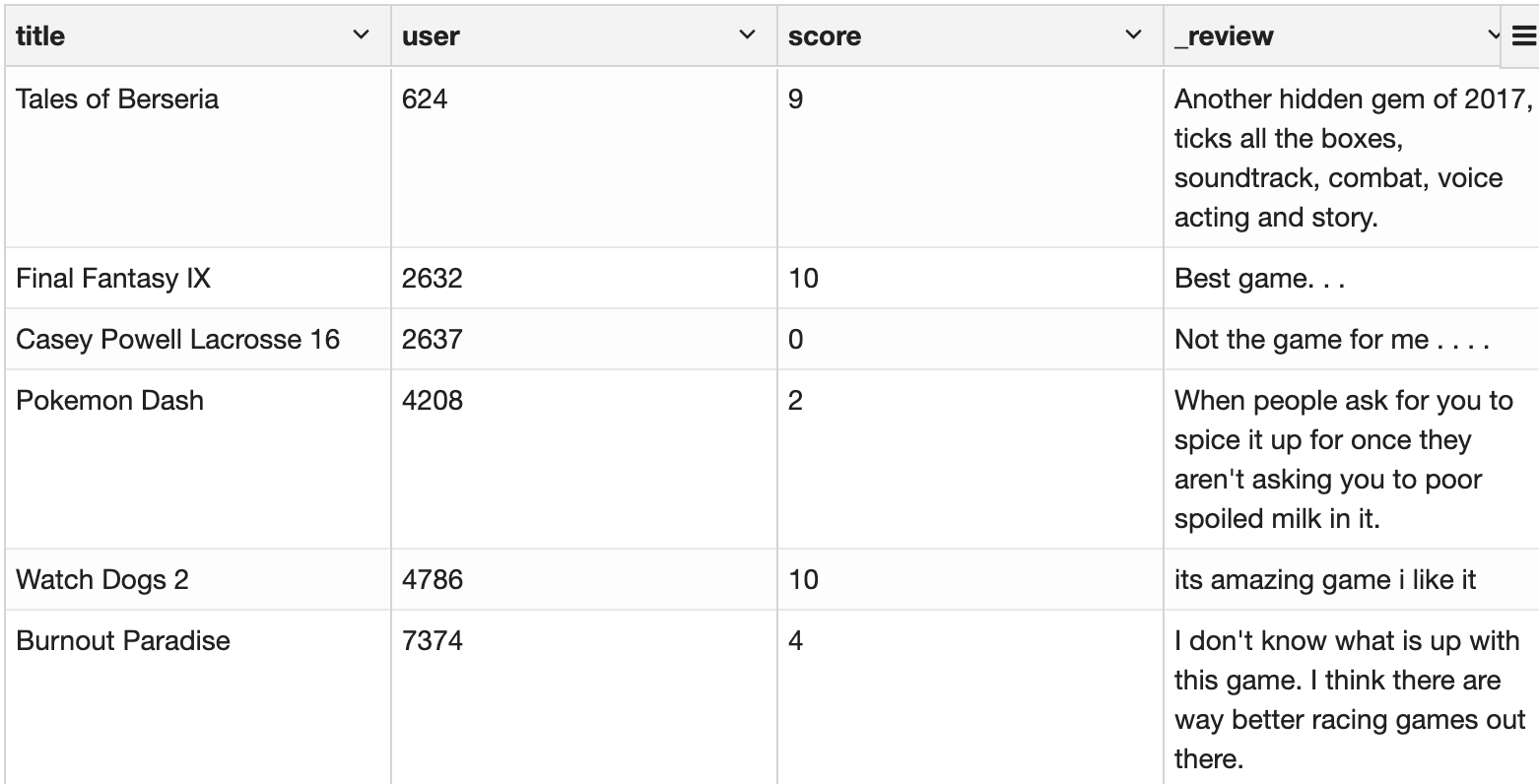 user id는 인덱스로 바꿨습니다.
user id는 인덱스로 바꿨습니다.
Classification Pipeline
이번 예제의 목표는 게임에 대한 유저의 리뷰가 긍정적인지, 부정적인지 모델이 분류하도록 학습시키는 것입니다. 기계가 이걸 할 줄 알면 어디에 쓸 수 있을까요? 방대한 양의 리뷰에서 악성 (의심) 댓글을 찾는다던지, 고객의 감정을 헤아려 적절한 응대를 한다던지 등의 다양한 활용이 있을 것 같습니다.
Preprocessing
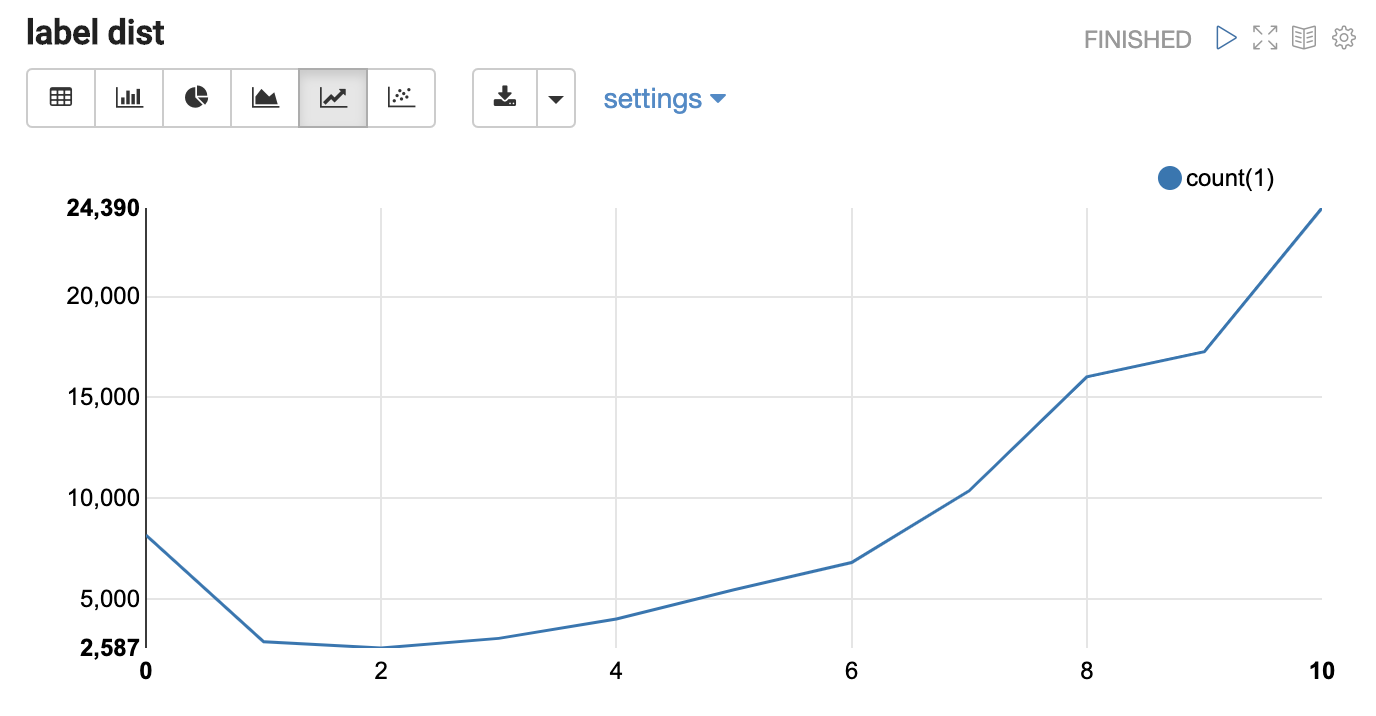
먼저 파일을 읽고, 각 레코드마다 id를 달아주고, score 컬럼으로 정답 라벨을 달아줬습니다. 십지선다 문제는 너무 어려울 듯하여 라벨 분포를 보고 임의로 리뷰가 긍정적인지(> 8, good), 부정적인지(< 5, bad), 아니면 이도 저도 아닌지(soso)로 나누었습니다. 성능이 너무 안 나와서 soso는 제외
import org.apache.spark.sql.functions._
import org.apache.spark.sql.Encoders
case class GameReview (
title: String
, user: String
, score: Int
, _review: String
, _corrupt_record: String
)
var df = spark.read
.option("header", "true")
.option("inferSchema", "true")
.option("multiLine", true)
.option("escape", "\"")
.schema(Encoders.product[GameReview].schema)
.csv("/data/user_detail.csv")
df = df.withColumn("id", monotonically_increasing_id())
.withColumn("target", expr("""
case
when score > 8 then 'good'
when score < 5 then 'bad'
else 'soso'
end
""")).where("target != 'soso'")
df.createOrReplaceTempView("df")
val Array(train, test) = df.randomSplit(Array(0.8, 0.2), seed = 543)
// 학습용, 테스트용으로 데이터를 나눴습니다.
여기까지는 지난번의 ETL 포스트를 보셨다면 익숙하시리라 생각합니다. 그럼 이제 어떤 단계를 거치는지 보겠습니다.
import org.apache.spark.ml.feature.
{StringIndexer, Tokenizer, StopWordsRemover, Word2Vec, CountVectorizer, IDF}
val indexer = new StringIndexer()
.setInputCol("target") // 이 컬럼을 보고
.setOutputCol("label") // 이 컬럼으로 변환해서 돌려줍니다.
.setHandleInvalid("keep") // "keep", "error" or "skip"
val tokenizer = new Tokenizer()
.setInputCol("_review") // text를
.setOutputCol("token") // token으로 자릅니다.
var remover = new StopWordsRemover // 얘는 위에 애들 처럼 하면 에러가 납니다.
remover = remover // 2.2 버전 버그인가 싶네요.
.setInputCol("token") // 잘린 token 중에
.setOutputCol("removed")// 무의미한 애들을 제거합니다.
자연어 처리에 익숙하신 분은 쓱 보시고 넘어가시면 되겠습니다. 익숙하지 않은 분, 혹은 기억이 가물가물하신 분을 위해 간단하게 이해할 수 있도록 정리해보겠습니다. SparkML의 API는 사용법이 거의 비슷합니다. 하나만 알면 나머지는 이거겠지.. 하면 대부분 맞습니다.
StringIndexer
target 컬럼에는 score에 따라 입력해준 good, soso, bad들이 들어있습니다. 우리는 이 값을 컴퓨터가 맞추기를 원하는데, 컴퓨터는 문자열보다는 숫자를 선호하기 때문에 StringIndexer로 변환해서 0, 1, 2로 바꿔줍니다. 라벨뿐만 아니라 문자열 피쳐에도 숫자 인덱스로 변환할 때 쓰면 됩니다.
그런데 학습할 때는 good, soso, bad 문자열만 들어왔는데, 실제로는 awesome과 같은 문자열이 들어올 수도 있겠죠? (여기서는 변환 대상이 라벨이니까 그럴일은 없지만요, 라벨이 없겠죠.) 그럴 때
.setHandleInvalid()로 어떻게 대처할지를 정해줄 수 있습니다.
tokenizer
마찬가지로 컴퓨터는 길게 쓰여있는 문자열을 보고서는 이해를 할 수가 없습니다. 컴퓨터가 이해하기 편하도록 바꿔주어야 하는데, 일단 MK는 밥을 먹는다라는 문장을 [MK는, 밥을, 먹는다]라는 토큰으로 나누어 줍니다.
remover
영어에는 a, the와 같은 관사가 있고, 한국어에는 은, 는, 이, 가, 을, 를 처럼 조사 등이 있죠. 이런 애들은 문장의 의미적인 부분보다는 문법적인 측면을 위해 사용됩니다. 우리의 목표는 이 문장이 긍정적인지, 부정적인지 알고 싶은 것이기 때문에 제외하였습니다. (목적에 따라 제외하지 않는 것이 더 나을 때도 있습니다) 위의 예제로 보자면 [MK, 밥, 먹는다] 정도가 되겠죠.
// word2vec route
val w2v = new Word2Vec()
.setInputCol("removed")
.setOutputCol("features")
// word count route
val tf = new CountVectorizer()
.setInputCol("removed")
.setOutputCol("tf")
val idf = new IDF()
.setInputCol("tf")
.setOutputCol("features")
word2vec
remover까지 거쳤다면 문장들이 핵심 단어들로 쪼개져서 배열의 형태로 변해 있을 겁니다. (위 예제에서는 transform을 하지 않고 객체 선언만 했기 때문에 아직 변하지는 않았습니다.)
word2vec을 간단히 설명하자면, 단어 목록의 패턴을 계산해서 단어와 단어 사이의 관계를 수치로 표현하는 방법입니다. 그래서 word to vector입니다. 예를 들어, [MK, 밥, 먹는다], [JK, 밥, 먹는다], [고양이, 소파, 눕는다]라는 단어 목록을 계산한다면, MK랑, JK는 밥을 먹는 애들이구나, 밥은 이런 애들에게 먹히는 거구나, 고양이는 MK랑 큰 연관이 없구나 등등이 숫자, 벡터로 표현이 됩니다.
굉장히 함축적으로 표현했기 때문에 깊게 알고 싶으시다면 좋은 자료를 보시는 것을 권장합니다.
Word2Vec의 학습 방식 - ratsgo’s blog
TF-IDF
문장(review)에 들어있는 모든 단어를 세면 그게 Term Frequency(TF)입니다. [이거 게임 정말 좋아 정말 최고야], [이거 게임 별로임]이라고 하면 아래 표처럼 개수를 셀 수 있습니다.
| idx | 이거 | 게임 | 정말 | 좋아 | 최고야 | 별로임 |
|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 2 | 1 | 1 | 0 |
| 1 | 1 | 1 | 0 | 1 | 0 | 1 |
숫자로 표현이 되어있기 때문에, 이것만으로도 충분히 학습 재료로 사용이 가능합니다.
모든 문장에 들어가 있는 단어는 사실 큰 의미가 없을 수 있습니다. 예를 들면, 게임 리뷰니까 게임이라는 단어는 너무 흔하게 나올 것이고, 이런 단어는 긍정 부정 판단에 도움이 안 될 것 같지 않나요? 이처럼 모든 Document에 포함된 단어의 비중을 줄이면 TF-IDF(Inverse Document Frequency)가 됩니다. 짧은데 무슨 문서(document)인가 할 수 있지만, 리뷰 대신 신문 기사 한 편 혹은 책 한 권이 들어갈 수도 있습니다.
| idx | 이거 | 게임 | 정말 | 좋아 | 최고야 | 별로임 |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0.8 | 0.4 | 0.4 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0.4 |
모든 doc에서 등장한 [이거, 게임]의 비중이 idf를 적용하니 감쪽같이 사라졌습니다.
위처럼 단순하게만 하지는 않고 실제로는 계산상 왜곡을 조절하기 위해 smoothing을 준다던지, 너무 급격한 변화를 줄이기 위해 log를 씌운다던지 하는 옵션을 주어서 계산합니다. 다 쓰고 보니 데이터는 영어인데 예제는 한국어네요
val sentenceData = spark.createDataFrame(Seq(
(0.0, "이거 게임 정말 좋아 정말 최고야"),
(1.0, "이거 게임 별로임")
)).toDF("label", "sentence")
val tokenizer = new Tokenizer()
.setInputCol("sentence")
.setOutputCol("token")
val tf = new CountVectorizer()
.setInputCol("token")
.setOutputCol("tf")
// .setVocabSize(3)
// .setMinDF(2)
val idf = new IDF()
.setInputCol("tf")
.setOutputCol("tf-idf")
// .setMinDocFreq(0)
val pipe_tf = new Pipeline()
.setStages(Array(tokenizer, tf, idf))
.fit(sentenceData)
val transformed = pipe_tf.transform(sentenceData)
transformed.drop("label", "sentence").createOrReplaceTempView("tf")
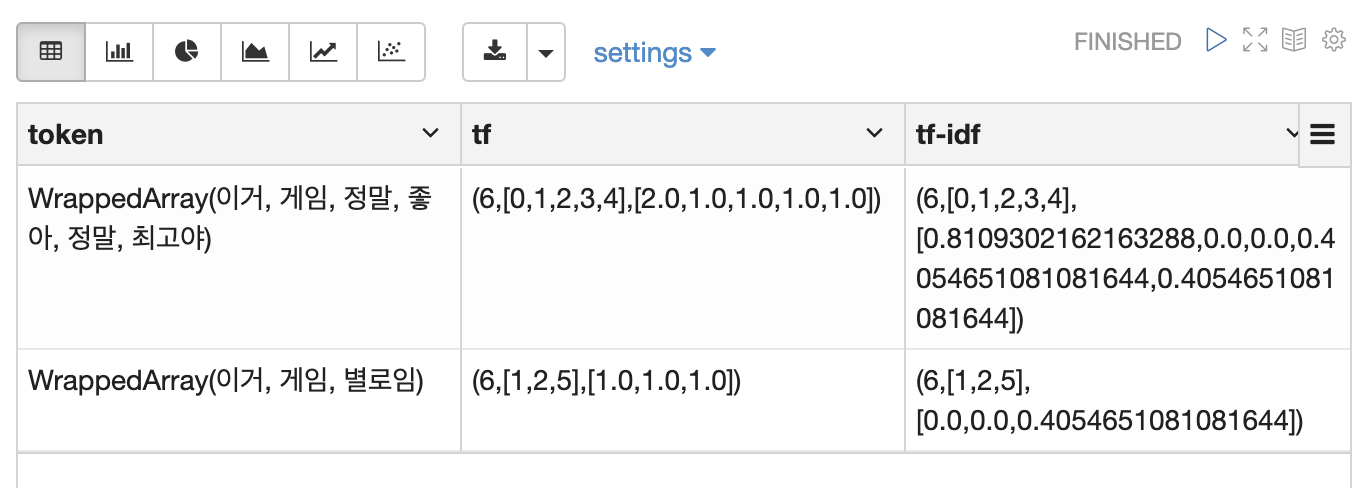 위 예제의 결과. sparse-vector라 조금 다르게 표현됩니다.
위 예제의 결과. sparse-vector라 조금 다르게 표현됩니다.
Pipeline
scikit-learn과 같은 라이브러리를 사용해보신 분들이라면 익숙하실 겁니다. 모든 단계에서 fit하고 transform할 필요 없이 한 번만 하면 pipeline에 명시한 순서대로 변형이 진행됩니다. 물론 pipeline 없이 단계별로도 fit, transform 할 수 있습니다. 여기서는 전처리 부분만 파이프라인에 넣었는데, 알고리즘도 포함시킬 수 있습니다.
import org.apache.spark.ml.Pipeline
val pipe_wv = new Pipeline()
.setStages(Array(indexer, tokenizer, remover, w2v))
.fit(train)
val pipe_tf = new Pipeline()
.setStages(Array(indexer, tokenizer, remover, tf, idf))
.fit(train)
val transformed_wv = pipe_wv.transform(train)
val transformed_tf = pipe_tf.transform(train)
w2v을 거치는 전처리와 tf-idf를 거치는 두 가지 방식으로 전처리 파이프라인을 만들어 보았습니다.
Model
자연어 분석에 자주 사용되는 나이브 베이즈와 가장 기본이 되는 로지스틱 회귀, 그리고 캐글 등의 경연에서 자주 사용되는 그레디언트 부스트 모델 등을 사용할 수 있습니다. 가짓수가 많지는 않지만 있을 건 다 있습니다. 무려 딥러닝도 스파크로 돌릴 수도 있습니다! (하지만 텐서나 토치를 추천합니다..)
// training
import org.apache.spark.ml.classification.
{NaiveBayes, LogisticRegression, GBTClassifier}
// LR
val lr = new LogisticRegression()
.setFeaturesCol("features")
.setLabelCol("label")
val wv_lr= lr.fit(transformed_wv)
val tf_lr= lr.fit(transformed_tf)
// NB
val nb = new NaiveBayes()
.setFeaturesCol("features")
.setLabelCol("label")
.fit(transformed_tf)
val tf_nb = new NaiveBayes()
.setFeaturesCol("tf")
.setLabelCol("label")
.fit(transformed_tf)
여기서는 간단한 로지스틱 회귀 모델과 전통적으로 자연어 처리에 많이 사용되는 나이브 베이즈 모델을 사용하겠습니다. 전처리와 동일한 방식으로 적용하면 됩니다. 물론 모델의 파라미터도 조작이 가능하지만 기본 값으로 해보겠습니다.
Evaluate
학습을 마치고서는 잘 되었는지 평가를 해야겠죠. 학습에 쓰이지 않은 데이터로 accuracy를 확인해보겠습니다.
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
// test
val test_wv = pipe_wv.transform(test)
val test_tf = pipe_tf.transform(test)
//LR
val predictWv = wv_lr.transform(test_wv)
val predictTf = tf_lr.transform(test_tf)
// NB
val predictNb = nb.transform(test_tf)
val predictTfNb = tf_nb.transform(test_tf)
for (i <- List(predictWv, predictTf, predictTfNb, predictIdfNb)){
var acc = evaluator.evaluate(i)
println(s"acc: $acc")
}
// result
acc: 0.7510406660262569
acc: 0.909622158181236
acc: 0.89905539545309
acc: 0.9165065642010887
Accuracy만으로는 일단 wv 보다는 tfidf 전처리가 낫고, 그중에서도 나이브 베이즈 모델로 TF 까지만 처리한 결과가 가장 좋네요. 잘 나온 결과를 더 자세히 보기 위해 mllib을 꺼내서 써보겠습니다.
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.sql.Row
val predictionAndLabels = predictTfNb.select("label", "prediction").rdd.map {
case Row(label:Double, prediction:Double) => (prediction, label)
}
// Instantiate metrics object
val metrics = new MulticlassMetrics(predictionAndLabels)
// Confusion matrix
println("Confusion matrix:")
println(metrics.confusionMatrix)
// Overall Statistics
val accuracy = metrics.accuracy
println("Summary Statistics")
println(s"Accuracy = $accuracy\n")
val labels = metrics.labels
labels.foreach { l =>
// Precision by label
println(s"Precision($l) = " + metrics.precision(l))
// Recall by label
println(s"Recall($l) = " + metrics.recall(l))
// False positive rate by label
println(s"FPR($l) = " + metrics.falsePositiveRate(l))
// F-measure by label
println(s"F1-Score($l) = " + metrics.fMeasure(l))
println("\n")
}
// Weighted stats
println(s"Weighted precision: ${metrics.weightedPrecision}")
println(s"Weighted recall: ${metrics.weightedRecall}")
println(s"Weighted F1 score: ${metrics.weightedFMeasure}")
println(s"Weighted false positive rate: ${metrics.weightedFalsePositiveRate}")
// result
Confusion matrix:
8089.0 251.0 // 긍정 리뷰 8089개 정답, 251개 오답!
792.0 3360.0 // 부정 리뷰 792개 오답, 3360개 정답!
Summary Statistics
Accuracy = 0.9165065642010887 // (8089 + 3360) / (8089 + 3360 + 251 + 792)
Precision(0.0) = 0.9108208535074879
Recall(0.0) = 0.9699040767386091
FPR(0.0) = 0.1907514450867052
F1-Score(0.0) = 0.9394344114743627
Precision(1.0) = 0.9304901689282747
Recall(1.0) = 0.8092485549132948
FPR(1.0) = 0.030095923261390888
F1-Score(1.0) = 0.8656447249774573
Weighted precision: 0.9173583973457129
Weighted recall: 0.9165065642010887
Weighted F1 score: 0.9149087327731819
Weighted false positive rate: 0.13735393254918477
뭔가 많아보이지만 metrics안에 있는 값들 프린트 찍은게 다 입니다. (공식문서에 있는 예제 그대로) 부정적 리뷰의 recall 값이 조금 아쉽지만 생각보다 괜찮네요. 분류 평가 지표의 의미에 대해서는 다른 포스트에서 정리하였습니다. 다중 분류 문제 성능 평가 방법 이해하기 [기본편]
Outro
나름 간단한 예제로 sparkML 튜토리얼을 작성해봤습니다. sparkML을 사용하는 사람이 적다 보니 사용하다가 의문이 생기면 막막할 때가 종종 있습니다. 하지만 공식 문서도 잘 되어있는 편이고, 또 찾아보면 어딘가에는 힌트가 있습니다. 많은 분들이 사용하셔서 꿀팁을 찾기가 더 쉬워졌으면 좋겠습니다. 그러니 스팤-엠엘 한번 써보시는 게 어떻습니까? 저도 열심히 써보겠습니다.
Leave a comment